-
[논문 리뷰] Revisiting Knowledge Distillation via Label Smoothing RegularizationKnowledge Distillation 2022. 4. 9. 01:39
이번 포스팅은 2020 CVPR에서 발표된 Revisiting Knowledge Distillation via Label Smoothing Regularization 논문을 리뷰해보려고 합니다. 해당 논문은 지식 증류(Knowledge distillation)가 분류 문제에서 정규화(Regularization) 기법으로 종종 사용되는 Label Smoothing기법의 한 종류라는 것을 주장하고, 이에 영감을 받아 Teacher-free 지식 증류 프레임워크를 제안합니다.
Introduction & Exploratory Experiments
지식 증류는 일반적으로 거대한 교사(Teacher) 네트워크의 "Dark knowledge"라고 불리는 지식을 경량화된 학생(Student) 네트워크에게 전달하여 성능을 향상시키는 것에 목적이 있습니다. 그러나, 본 논문의 저자들은 Softmax를 거쳐 나온 Logits을 전달하는 지식 증류가 Label Smoothing 기법과 유사하다는 점에서 다음과 같은 두 가지 실험을 수행합니다. (Dark knowledge: 클래스 간의 similarity information을 의미함, ex. 고양이, 호랑이 클래스는 유사한 특징을 많이 가지고 있고, 그렇기 때문에 교사의 Logits이 학생에게 클래스 간의 유사성 정보를 배울 수 있도록 함.)
(1) 가벼운 학생 네트워크의 지식을 무거운 교사 네트워크로 전달하는, 즉 일반적인 지식 증류를 역으로 하였을 때에도 성능 향상이 발생한다.
(2) 학생 네트워크보다 훨씬 성능이 낮은 네트워크를 교사로 사용했을 때에도 학생 네트워크의 성능을 향상시킬 수 있다.
저자들은 위의 두 실험이 입증된다면, 출력을 전달하는 지식 증류가 "Dark knowledge"를 전달하는 것이 아니라 Label Smoothing의 한 종류로서 정규화 효과로 인해 성능 향상이 발생한다고 주장합니다.
아래 Figure의 (b)와 (c) 그림과 같이 교사와 학생 네트워크의 구조를 설정하고 실험을 수행하였습니다.

먼저 (1)번 케이스를 Re-KD(Reverse-KD)라고 표현하고, 이에 대한 실험 결과는 다음과 같습니다.
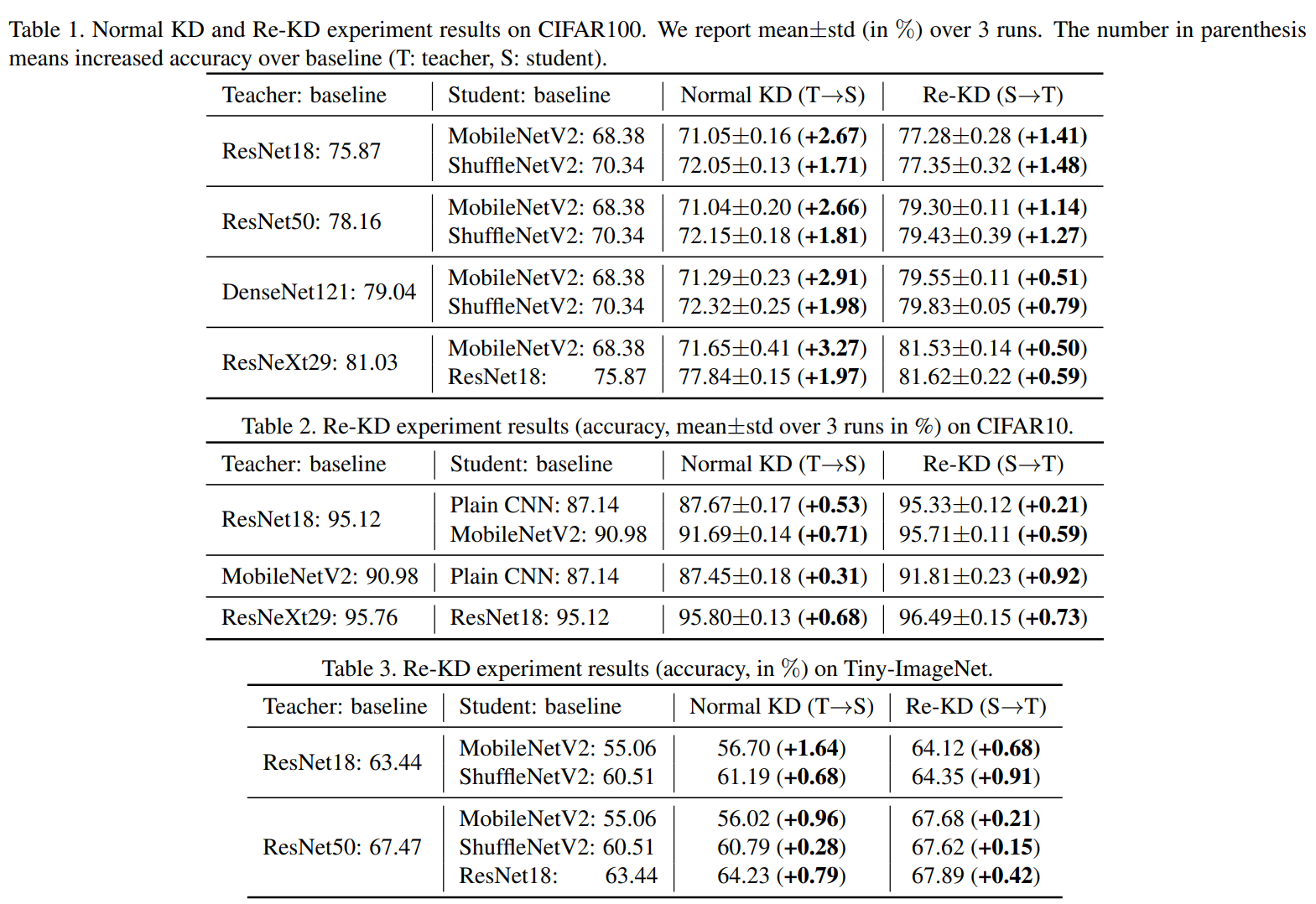
Table1은 CIFAR100, Table2는 CIFAR10, Table3은 Tiny-ImageNet에 대한 실험이고, 해당 결과는 경량화된 학생 네트워크가 교사 네트워크에게 지식을 전달하는 Re-KD의 경우에도 성능이 향상된다는 것을 보여줍니다. 일반적인 지식증류인 Normal KD가 성능 향상이 Re-KD보다 높긴 하지만, Normal KD의 경우 Student 모델의 성능 향상폭을 의미하는 것이고 Re-KD는 Teacher 모델의 성능 향상폭을 의미합니다. 예를 들어, Table1의 첫 번째 행을 보면 Normal KD의 경우 Student의 성능이 68.38에서 71.05로 +2.67 증가했지만, Re-KD의 경우 Teacher의 성능인 75.87에서 77.28로 1.41 증가했다는 것을 의미합니다. 즉, 성능 향상폭 자체는 Normal KD가 높지만, 기본 성능이 68.38과 75.87로 출발점이 다르다는 것을 감안해야합니다. 극단적이긴 예시이긴 하지만, 90%에서 1% 향상과 60%에서 1% 향상을 비교하면 90%에서 1% 향상한 것이 더 효과적이라고 생각할 수 있습니다. 그리고 그러한 점을 제외하더라도 Table2와 Table3의 일부 케이스에서는 Re-KD가 더 높은 향상폭을 가진 것이 존재합니다.
다만, 더 높은 향상폭을 가지는 결과를 보면 대부분 교사와 학생 네트워크의 성능이 크게 차이 나지 않은 경우에 한정되어 있습니다 (Table2 - Row 3,4 / Table3 - Row2). 더 좋은 성능을 가지는 교사 네트워크로 지식 증류를 수행하면 Normal KD의 성능 향상폭이 더 커지지 않을까라는 개인적인 생각이 들었습니다.
다음으로 (2)번 케이스는 학습을 덜시킨 큰 네트워크를 교사로 설정한 경우를 De-KD로 표현하여 실험하였습니다.

개인적으로는 Re-KD보다 De-KD의 실험 결과가 놀라웠습니다. 첫 번째 15.48의 정확도를 가지는 ResNet18을 교사로 사용했을 때, 학생인 MobileNetV2의 성능이 2.27 증가하였고, 이는 Table1의 Normal KD를 수행했을 때인 2.67의 증가폭과 크게 차이가 안나는 것을 확인할 수 있습니다. 45.82의 정확도를 가지는 ResNet50을 교사로 사용했을 때는, 3.09의 증가폭으로 Normal KD의 증가폭인 2.66보다 높은 경우도 있습니다. De-KD의 경우는 대부분의 실험에서 Normal-KD와 유사한 성능을 보이는 것을 보여줍니다.
위 실험적 발견에 따라 지식 증류에서 "Dark knowledge"가 단지 클래스 간의 유사성 정보만을 가지고 있기 때문에 잘 작동하는 것이 아니라고 주장합니다. De-KD의 경우에서처럼 성능이 매우 낮은 교사 네트워크는 클래스 간의 유사성 정보를 제대로 포함하지 못하기 때문에, 유사성 정보가 부족한 경우에도 교사는 학생의 성능 향상을 이끄는 "Dark knowledge"를 전달할 수 있다고 주장합니다.
위와 같은 실험적 발견에 기반하여, 저자들은 지식 증류와 Label Smoothing 정규화 기법의 관계에 대해 이론적으로도 설명합니다.
Knowledge Distillation (KD) and Label Smoothing Regularization (LSR)
먼저 Label Smoothing (LS)의 수식을 표현하면 아래와 같습니다.

왼쪽항은 일반적인 q와 p 출력간의 Cross Entropy이고, 오른쪽 항은 LSR을 의미합니다. $\alpha$는 가중치이고, $u$는 uniform distribution을 통해 타겟 클래스를 제외한 나머지 클래스에 골고루 값이 들어가 있는 분포를 의미합니다. 따라서, 출력 $p$와 LS가 적용된 Ground Truth $u$간의 KL divergence를 계산하게 됩니다.
다음으로 KD에 대한 수식은 다음과 같습니다.
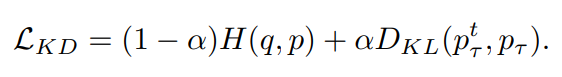
왼쪽항은 동일하게 Cross Entropy이고, 오른쪽 항은 교사와 학생 네트워크 출력 분포간의 KL divergence를 나타냅니다. 위 두식의 차이는 학습된 교사의 분포인 $p_{\tau}^{t}$와 LS된 분포인 $u$ 부분입니다. 만약 출력 분포의 정도를 조정하는 Temperature $\tau$를 매우 커지게 하면 출력의 분포가 스무딩되면서 KD의 식은 LS와 유사해집니다.
이러한 식에 따라서 저자들은 KD가 LSR의 특수한 케이스라고 얘기합니다.
저자들은 실험적, 이론적 입증에 기반하여, 학생 네트워크가 스스로(Self-training) 또는 manually-design된 정규화 분포로부터 학습할 수 있는 Teacher-free 지식 증류 프레임워크를 제안합니다.
Method (Teacher-free Knowledge Distillation)
(1) Self-training KD
앞에서 실험한 바와 같이, 지식 증류는 작은 네트워크로부터 얻는 지식 (Re-KD), 학습이 덜 된 (De-KD) 큰 네트워크로부터 얻는 지식 모두 유용합니다. 따라서, 저자들은 매우 강력한 교사 모델을 이용할 수 없을 때, 자기 자신으로부터 KD를 수행하는 Self-training 방식의 KD 방법을 제안합니다. 먼저 A라는 구조의 모델을 학습시켜 교사로 두고, A와 동일한 구조인 다른 모델을 학생으로 두어 KD를 수행합니다.
해당 방법은 그냥 일반적인 KD와 다를바가 없지만, 단순히 같은 구조의 네트워크로(또는 더 좋지 않은 성능이어도) 증류해도 KD의 효과를 얻을 수 있다는 주장때문에 제안을 한 것 같습니다. 방법 자체는 참신하지 않습니다.
(2) Manually Teacher-free KD (Tf-KD)
저자들은 KD와 LSR을 결합하는 방식으로 간단한 교사 모델을 구축하는 방법을 제안합니다.
먼저 아래 식과 같이 일반적인 LSR을 취해줍니다. 이 때, 정답 Class에 대한 값은 $a$=0.9 이상으로 설정해준다고 합니다.
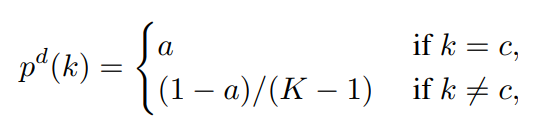
그 후, 20이상으로 높은 Temperature $\tau$를 통해 정답 분포를 Smoothing 시켜줍니다.

Experiments
제안하는 두 Teacher-free 방법인 Tf-KD$_{self}$, Tf-KD$_{reg}$에 대한 실험은 모두 Normal KD보다 높은 성능을 보이고 있다고 보여줍니다.
1) Tf-KD$_{self}$

Self-training 버전의 경우에는 Normal KD와 유사한 성능을 보여줍니다. 다만, 더 다양한 실험 세팅(더 Powerful한 교사 네트워크, Baseline 모델이 더 낮은 or 높은 성능, ...) 에서도 일관되게 비슷한 성능이 나올지에 대해서는 의문이 들었습니다.
2) Tf-KD$_{reg}$

LSR+KD 버전의 경우에서도 Normal KD와 유사한 성능을 보여줍니다. 테이블의 가장 오른쪽에 기록된 일반적인 LSR만 적용했을 때는 성능 향상폭이 적습니다. 저자들은 해당 방법이 교사 네트워크를 학습해야하는 추가적인 연산량없이도 그만큼 좋은 성능 향상을 낼 수 있었다는 것에 의의를 둡니다.
Conclusion
지금까지의 성공적인 지식 증류가 교사의 카테고리간 유사성 정보만을 전달하는 것보다는 Soft target을 정규화하는 덕분이라고 주장합니다. KD와 LSR의 관계에 기반하여 Teacher-free KD를 제안하고, 학습에 엄청난 리소스가 필요한 매우 강력한 모델이 없을 경우, 해당 방법을 통해서 학습을 수행하는 것이 효과적이라고 얘기합니다.
나의 결론:
저자들이 주장하는 바를 입증하기 위해서 Re-KD나 De-KD같은 실험을 통해 보여준 전개는 흥미로웠으나, 제안하는 Teacher-free KD 방법이 참신하지는 않았다고 생각한다. 그리고 Teacher-free KD 관련 실험 역시도 더 다양한 셋팅과 의미있는 비교가 있었으면 주장이 조금 더 설득력이 있었을 것 같다. 마지막으로, 해당 논문은 출력을 증류하는 관점에서 지식 증류가 클래스 간의 유사성 정보보다는 정규화 효과때문에 성능 향상이 있었다고 하는데, 피쳐를 증류하는 관점에서는 피쳐맵간의 유사성 정보를 토대로 여전히 클래스의 유사성 정보를 배우지 않을까? 하는 생각이 들었다.
'Knowledge Distillation' 카테고리의 다른 글
[논문 리뷰] Student Customized Knowledge Distillation: Bridging the Gap Between Student and Teacher (0) 2022.04.11 [논문 리뷰] A Comprehensive Overhaul of Feature Distillation (0) 2022.04.08