-
딥러닝 모델 경량화에서 한 축을 담당하고 있는 Knowledge Distillation 관련 논문을 차근차근 리뷰하려고 합니다. 먼저, 첫 번째로는 2019 ICCV에서 네이버 클로바가 발표한 A Comprehensive Overhaul of Feature Distillation (OFD) 논문을 정리해보려고 합니다. OFD는 2022년인 현재까지도 Feature Distillation 방법 중에서 높은 순위를 기록하고 있습니다.
Abstract
지식 증류(Knowledge distillation)의 한 갈래인 피쳐 증류(Feature distillation)를 효과적으로 수행하기 위해 여러 가지 측면(Teacher transform, Student transform, distillation feature position, distance function)을 고려한 방법론을 제안합니다. 해당 방법은 1) margin ReLU라는 새로운 피쳐 변환(transform) 방법과 2) 증류할 피쳐의 새로운 위치, 그리고 3) 학생 (Student) 네트워크의 압축(Compression)에 역효과를 주는 중복된 정보를 방지하는 partial L2 distance function을 포함합니다. 실험 결과는 이미지넷 분류(Classification)를 포함한 객체 검출(Object Detection), 객체 분할(Semantic Segmentation) 등의 모든 태스크에서 유의미한 성능 향상을 보여줍니다.
Introduction
Hinton이 처음 제안한 지식 증류(KD)는 교사(Teacher) 네트워크의 Softmax 출력을 학생(Student) 네트워크에게 추가적인 Supervision으로 사용하는 방법입니다. 이는 교사와 학생 네트워크의 출력이 서로 동일한 차원을 가지고 있기 때문에 쉽게 적용될 수 있습니다. (**피쳐 증류는 일반적으로 교사와 학생의 채널 차원이 다릅니다) 그러나, 고성능 교사 네트워크의 출력은 Ground Truth와 크게 다르지 않기 때문에, 오직 교사의 출력 지식만을 전달하는 것은 큰 성능 향상을 기대하기는 어렵습니다. 교사 네트워크가 지니고 있는 지식을 더 효과적으로 전달하기 위해, 출력 증류 대신 피쳐 증류 기반의 여러 방법들이 연구되어 왔습니다.
FitNets이 학생 네트워크가 교사 네트워크의 히든(Hidden) 피쳐를 모방하는 피쳐 증류를 처음으로 제안한 연구입니다. 이후, 교사 네트워크의 피쳐를 차원이 축소된 표현(Representation)으로 변환하여 그 정보를 학생 네트워크에게 전달하는 방법들 (AT-Attention Transfer, etc)이 제안되었습니다. 이는 추상화된(Abstracted) 피쳐 표현을 증류하는 것이 성능 향상에 유의미하다는 결과를 보여줍니다. AT와는 대조적으로 Factor Tranafer (FT)와 Activation Boundary (AB)는 전달하는 정보의 양을 증가시킵니다. FT는 피쳐를 변환하는 과정에서 발생하는 정보의 손실을 완화하기 위해 Auto-Encoder 구조를 사용하여 피쳐를 "factor"라고 하는 인코딩하여 지식을 전달합니다. AB는 피쳐의 히든 값의 크기보다는 단순히 음수, 양수, 0과 같이 부호(Sign)에만 집중하여 학생이 교사 네트워크를 따라할 수 있도록 Loss를 설정합니다. 비록 FT와 AB가 성능 향상에 기여했지만, 교사 네트워크의 피쳐 값을 변환하기 때문에 여전히 성능 개선의 여지가 남아있습니다. (**피쳐를 변환하는 것은 전달하게되는 지식의 변형을 야기할 수 있으므로)
본 논문에서는 1) 교사의 피쳐 변환, 2) 학생의 피쳐 변환, 3) 증류할 피쳐의 위치 4) distance function, 네 가지 관점을 포함하는 새로운 지식 증류 Loss를 제안합니다.
1) Teacher transform: 피쳐 증류를 수행하기 위해, 많은 기존 연구들에서 교사의 피쳐를 변환합니다. 다만 피쳐를 변환하는 것은 교사 피쳐맵의 중요한 정보를 잃어버릴 수 있기 때문에 주의가 필요합니다. 저자들은 교사 피쳐맵에서 불필요한 정보와 중요한 정보가 모두 포함되어 있기 때문에, 이 둘을 구분하고 중요한 정보를 잃지 않는 것이 중요하다고 합니다. 이를 위해 margin ReLU로 불리는 피쳐 변환 방법을 제안합니다. margin ReLU는 Positive한 값을 중요한 정보로 보아 유지하고, Negative 값을 불필요한 정보로 보아 억제시키는 역할을 수행합니다.
2) Student transform: 일반적으로 학생 피쳐 변환은 교사 피쳐 변환과 동일하도록 하는 연구 (AT, FSP, FT, ...)가 많고, FitNets과 AB는 1x1 conv를 사용하여 학생 피쳐를 교사의 피쳐 차원에 맞추어 줍니다. 이러한 경우 학생 피쳐의 정보가 감소하지 않고, 오히려 커지게 되므로 정보의 손실이 발생하지 않습니다. 따라서, 본 논문에서는 FitNets와 동일하게 학생 피쳐 변환으로 1x1 conv를 사용하여 차원을 맞추어줍니다.
3) Distillation feature position: 일반적으로 분류 문제에서 CNN 구조들은 네 개의 블락으로 구성되어 있습니다. 기존 연구들은 대부분 각 블락마다의 마지막 레이어를 거친 피쳐를 증류합니다. 보통의 레이어는 Conv-BN-ReLU를 거치는데, ReLU를 거치면 Negative 정보는 사라지고 Positive 정보만 살아남게 됩니다. 따라서, 저자들은 Negative 정보도 함께 보존할 수 있도록 ReLU를 거치기 이전 위치의 피쳐를 증류하는 방법을 제안하고, 이를 Pre-ReLU라고 표현합니다.
4) Distance function: 일반적으로 지식 증류에서 교사와 학생 피쳐간에는 L1 또는 L2 loss를 사용합니다. 그러나 본 연구에서 제안한 pre-ReLU 위치의 피쳐는 불필요한 Negative 정보를 함께 포함하고 있습니다. 따라서, 저자들은 해당 Negative 정보를 무작정 반영하기 보다는, 학생의 음수 값이 교사의 음수 값보다 작은 경우에는 Loss가 0이 되게 하는 Loss function을 설계합니다.
Approach
1) Distillation position: 최근의 뉴럴 네트워크에서 활성화 함수(Activation function)는 필수적으로 사용되고, 그 중 Negative value를 0으로 만들어 불필요한 정보를 역전파 하지않는 ReLU가 주로 사용됩니다. 저자들은 ReLU를 고려하여 증류의 위치를 정하는 것이 교사의 필요한 정보만을 학생 네트워크에 전달할 수 있는 중요한 요소라고 얘기합니다. 기존 연구들은 ReLU의 유무에 상관없이 CNN 각 블락의 마지막에 있는 피쳐를 증류합니다. 제안하는 방법에서는 아래 그림에서 보는 것과 같이 각 블락의 첫 번째 ReLU와 블록의 끝 사이에 있는 위치의 피쳐를 증류합니다.

Simple, Residual, Pre-activation, Pyramid block과 같이 다양한 구조에서 Pre-ReLU 위치의 피쳐를 가져오는 방법을 보여줍니다. 기존의 Pre-activation이나 Pyramid와 같이 블락 마지막에 활성화함수(ReLU)를 사용하지 않는 구조에서는 BatchNorm, ReLU, 1x1 Conv을 적절히 추가하여 해당 피쳐를 증류합니다. 이러한 위치의 피쳐를 증류함에 따라 ReLU를 통해 사라지는 정보를 보존할 수 있게되고 이는 유의미한 성능의 증가를 보여준다고 얘기합니다.
2) Loss function: 본 Section에서는 Introduction에서 설명했던 Teacher transform, Student transform, Distance function을 모두 고려하여 Loss function을 설계하는 방법에 대해 서술합니다.
먼저 피쳐의 변환관점에서, 교사의 피쳐 값이 Positive이면 학생은 해당 값을 따라하도록 학습해야합니다. 반대로 피쳐가 Negative 값을 가지면 마찬가지로 학생도 해당 음수 값을 따라하게 됩니다. 하지만 기존 연구인 Heo et al. (AB)에서는 학생 피쳐의 값이 음수일 때 Margin을 주어야한다고 얘기합니다. 따라서, Teacher transform은 양수의 값을 보존하면서 Negative 값에는 Margin을 주어 보정해야한다고 얘기합니다.

Margin ReLU는 위 식으로 표현할 수 있고, m은 0보다 작은 margin 값입니다.

위 그림의 가장 오른쪽과 같이 음수값에 대해 m보다 작은 음수값에 대해서는 m이라는 한계를 정해주게 됩니다. Negative 값에 margin을 정해주는 것은 교사의 Negative 값을 있는 그대로 배우는 것보다 쉽게 따라할 수 있기 때문이라고 얘기합니다. 그렇다면 Margin value m을 어떤 값으로 정해야하는지도 알아야겠죠.
m은 Activation의 Negative value 값들의 채널별 기대값으로 구해지게 됩니다. 기대값은 교사 네트워크 각 블락의 마지막 ReLU 직전의 Batch Norm 레이어에 있는 채널별 평균과 분산 파라미터 값들을 가져와서 계산하게 됩니다. 해당 부분에 대한 더 자세한 내용은 논문의 Appendix.A에 자세히 나와있으므로 궁금하시면 참고하시면 될 것 같습니다.
학생 피쳐의 변환은 FitNets와 동일하게 1x1 Conv와 Batch Norm을 사용하여, 교사 피쳐의 채널 수와 동일하게 맞추어줍니다. Introduction에서도 언급했듯이 채널을 늘림으로써 정보 손실이 발생하지 않는다고 합니다.
마지막으로 교사와 학생 피쳐를 어떻게 Loss로 계산할지에 대한 부분인 거리 함수(Distance function)에 대해 언급합니다. 본 논문에서는 기존 연구와는 다르게 ReLU 이전의 피쳐를 증류하기 때문에, 이 부분을 고려하여 거리 함수를 설계하는데요. 교사의 피쳐에서, Positive 값들은 해당 값을 정확하게 따라할 수 있도록 해야하지만, Negative 값들은 그렇지 않아도 됩니다. 예를 들어, 교사 피쳐의 한 위치의 값이 -5라고 해봅시다. 이 때, 학생 피쳐의 해당 위치의 값이 -2인 경우는 교사의 -5보다 값이 크기 때문에 -5로 줄어들 수 있도록 Loss를 주어야 합니다. 반대로 만약 학생 피쳐의 값이 -10인 경우는 Loss를 0으로 주어 역전파에서 영향이 가지 않도록 합니다. 이는 다음 레이어인 ReLU를 통과하게 되면서 교사의 -5나 학생의 -10 값이 0으로 동일하게 블락되기 때문이라고 합니다.
이 부분이 약간 이해가 되지 않았는데, 제가 나름 생각해본 결과로는 결국 학생은 교사의 정보를 잘 따라할 수 있어야 하는데, 특히 음수 값을 가지는 뉴런은 억제되어야 하는 부분을 나타냅니다. 그렇기 때문에 학생이 -2의 값을 가질 때는 교사가 억제했던 강도인 -5만큼 강하게 억제할 수 있도록 배워야하지만, -10의 값을 가질 때는 -5 이상으로 억제할 필요는 없기 때문에 아래와 같은 거리 함수를 설계한 것 같습니다.

위에서 언급한 케이스를 제외한 나머지의 경우에는 일반적인 L2 거리 함수를 사용하여 Loss를 계산합니다.

최종적으로, 본 논문에서 제안하는 Teacher transform($\sigma_{m_{c}}$), Student transform($r$), Distance function($d_p$)를 종합한 증류 Loss는 위와 같이 정리됩니다.
3) Batch normalization: 저자들은 지식 증류에서 배치 정규화의 영향에 대해서도 조사하였는데요. 요즘 배치 정규화는 학습의 안정성을 위해 대부분의 네트워크에서 사용하고 있습니다. 저자들은 배치 정규화가 학습(Training) 모드와 평가(Evaluation) 모드에서의 파라미터가 서로 다르다는 것에 집중합니다. 일반적으로 지식증류에서 교사 네트워크는 Pre-train을 시켜놓고 배치 정규화는 평가 모드에서 출력 지식을 전달하게 됩니다. 그러나, 학생 네트워크는 학습을 수행해야 하므로 배치 정규화가 학습 모드에서 출력 지식을 받아들이게 됩니다. 이는 교사 네트워크는 전체 이미지를 통해서 학습되어진 배치 정규화의 평균과 분산 파라미터를 고려하여 피쳐가 전달되는 반면에, 학생 네트워크는 Mini-Batch 별로 계속해서 배치 정규화의 파라미터가 달라지게 되므로 교사와 학생의 Normalization이 동일하지 않게 됩니다. 따라서, 교사 네트워크의 배치 정규화를 학습 모드로 둔 상태에서 지식 증류를 수행하였고, 이로 인해 추가적인 성능 증가가 있었다고 합니다.
Experiments
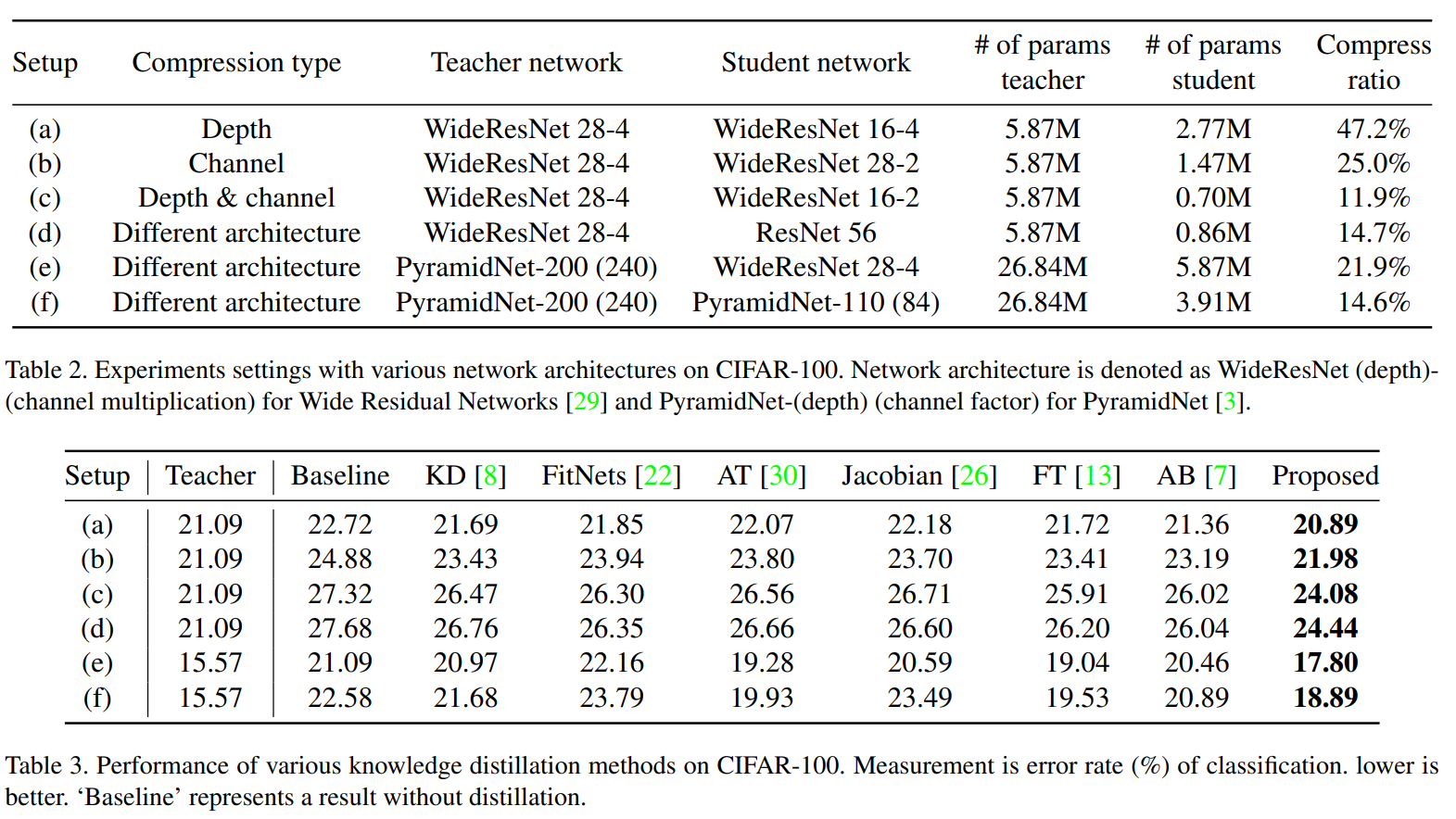
6가지의 실험 세팅에 대해 기존 피쳐 증류 방법들과 비교했을 때, 가장 좋은 성능을 보여줍니다. CIFAR-100 데이터셋 외에도 ImageNet-1k, Semantic Segmentation, Object Detection 등에서도 유의미한 성능 향상이 있다고 보여줍니다.
단순 실험에 대한 부분보다 분석을 수행한 부분이 흥미로웠는데요.
(1) Teacher-student similarity: 교사의 피쳐 증류를 통해 학생이 교사를 잘 따라하고 있는지에 대한 지표로, 교사와 학생 출력 분포의 유사도(KL Divergence)에 대해서 계산하는 실험을 수행합니다.

위 테이블은 CIFAR-100 데이터셋에 대해 교사와 학생간의 KL Divergence와 Error rate (100-Accuracy, %)을 함께 보여줍니다. KL Divergence의 경우 두 출력 분포가 완전히 동일하면 0이 되므로, 작을수록 유사하다는 것을 의미합니다. FitNets과 AB는 Baseline의 KLD 값보다 더 크지만 Error rate은 더 낮습니다. 이는 학생 네트워크가 교사 네트워트를 따라하는 어려웠다는 결과라고 설명합니다. 반면에 KD, AT, Jacobian, FT 등은 KLD 값이 줄어들었고, 이는 교사와 학생간의 유사성이 높아졌다는 것을 의미합니다. 다만, 본 논문에서 제안하는 방법이 교사와 학생을 가장 유사하게 만들었고, 이는 성능 향상의 주요한 원인이 되었다고 얘기합니다.
(2) Ablation study: 각 모듈이 성능 향상에 미치는 정도를 조사하기 위해 아래 테이블과 같이 실험을 수행하였는데요. 실험 결과 Pre-ReLU 위치를 증류하는 방법이 -1.56으로 가장 영향이 컸고, 다음으로 Distance function, 그리고 교사 배치 정규화의 학습 모드 순으로 영향이 있었습니다.
