-
[논문정리] RCNN, Fast RCNN, Faster RCNN 핵심!Object Detection 2021. 5. 30. 01:06
이번 포스팅은 Object Detection 중 2-Stage Detector의 큰 흐름이라고 할 수 있는 R-CNN 계열에 대해 정리해보겠습니다. 이미 블로그, 유튜브를 포함한 많은 곳에서 R-CNN 계열을 설명하고 있으므로, 이번 포스팅에서는 제가 공부하면서 명확하게 이해되지 않았던 부분을 다루면서 진행해보도록 하겠습니다.
먼저, 2-Stage Detector인 R-CNN 계열은 공통적으로 아래와 같은 프로세스를 가지고 있습니다.

1-Stage Detector와 비교해서 물체가 있을법한 영역을 제안해주는 Region Proposal 단계가 존재합니다. 이후 해당 영역의 이미지로부터 Feature를 추출하고 물체의 클래스를 맞추는 Classification 및 물체의 위치를 찾아내는 Regression을 수행합니다.
R-CNN

위는 R-CNN 논문에 나와있는 그림과 나동빈님의 유튜브를 참고하여 R-CNN의 전반적인 프로세스를 재구성한 그림입니다. 먼저 R-CNN에서는 Selective Search (Region Proposal)라는 Computer vision 알고리즘으로 물체가 존재할 것 같은 영역을 제안해줍니다. 위의 그림에서 초록색 박스를 제안해준다고 생각하면 될 것 같습니다. 위 그림에서는 편의를 위해 초록색 박스가 세 개만 있지만, 실제 Selective Search를 수행하면 한 이미지당 2천개 가량의 영역(박스)이 제안된다고 합니다. 이후, 각 영역별로 영역을 Crop하고 동일한 사이즈로 변형시키게 됩니다. 이 때, 동일한 사이즈로 변형하는 이유는 이후 단계에서 Classification이나 Regression을 하기위해 고정된 길이의 벡터로 만들어주기 위해서입니다. Fast R-CNN에서는 고정된 사이즈 문제를 해결하기 위해 ROI Pooling이라는 기법을 사용하니 차이점을 기억해주시면 되겠습니다. 이후, 위 그림에서와 같이 각 영역별로 Crop & Resize된 이미지를 각각 CNN에 넣어 고정된 길이(Fixed Length)의 벡터로 Feature를 추출하게 됩니다. 따라서, 이미지마다 3번(or 2천번)의 CNN을 수행하게 됩니다. 각 이미지마다 2천 번의 CNN을 수행하기 때문에 속도가 매우 느립니다. Fast R-CNN에서는 이 부분을 해결한다고 생각하시면 되겠습니다. 이후, 구해놓은 고정 길이의 벡터로 Classification과 Regression을 수행합니다. 이 때, Classification은 Total Class 수 만큼의 이진 SVM 분류기를 사용하였습니다. 이 논문이 나왔을 당시에는 CNN보다 여전히 SVM의 성능이 좋았기 때문에 분류기로 SVM을 사용했다고 합니다.
Fast R-CNN

Fast R-CNN은 이름에서도 알 수 있듯이 R-CNN의 단점인 매우 느린 속도를 개선한 논문입니다. 기존 R-CNN과 마찬가지로 Selective Search를 사용하여 영역을 제안(Region Proposal) 하였으나, 차이점은 간단하게 CNN을 병렬적으로 수행하느냐 순차적으로 수행하느냐라고 생각해볼 수 있습니다. 기존 R-CNN같은 경우 CNN을 통과하고 고정된 길이의 벡터를 얻기위해, Selective Search로부터 얻어진 2천개의 영역을 각각 Crop & Resize하여 동일한 사이즈를 입력으로 사용할 수 밖에 없었습니다. 하지만, 한 이미지당 2천번의 CNN을 수행하므로 매우 느릴 수 밖에 없었고, 이를 해결하기 위해 Fast R-CNN에서는 해당 영역(초록색 박스)의 Feature를 원본 이미지에서 추출(Crop)하는 것이 아니라 Feature Map단에서 추출합니다. 그렇기 때문에, 입력 이미지마다 단 한번의 CNN만을 수행하면 됩니다. 그리고 Feature Map에 해당 영역을 RoI Projection하면, 원본에서 Selective Search로 제안된 영역을 Feature Map Level에 투영시킬 수 있습니다. RoI Projection이 가능한 이유는 CNN(Convolution)이 Local한 특징을 부분적으로 Aggregation하여, Translation equivariant*한 성질을 가지고 있기 때문입니다. Feature Map의 특정 그리드(픽셀)가 원본 이미지의 특정 영역들이 합쳐졌다고 생각하시면 이해하기 쉬울 것 같습니다. 따라서, Feature Map이 입력 이미지에 비해 줄어든 비율만큼 영역(초록색 박스)을 줄여서 투영시켜 줍니다.
*Translation equivariant란 입력의 Translation(변환) 달라지면 출력도 마찬가지로 달라지는 것을 의미합니다. 반대의 의미인 Translation Invariant란 입력의 Translation이 달라져도 출력은 마찬가지인 것을 의미합니다. 대표적으로 Classification은 고양이 사진이 회전되어도 같은 고양이라는 Class로 예측하기 때문에 Translation Invariant한 성질을 가진다고 할 수 있습니다. (Fully-Connected Layer, Pooling Layer가 Translation Invariant한 성질을 지니고 있습니다.)
이후, Fast R-CNN에서 가장 핵심 아이디어인 RoI Pooling을 사용하게 됩니다. 기존에 Crop & Resize하여 동일한 사이즈를 입력으로 사용한 이유는 FC Layer로 들어가는 입력이 고정이기 때문이었습니다. 하지만, 실제로는 CNN의 입력이 고정일 필요는 없고, FC Layer 이전에만 고정 크기로 맞춰주면 문제가 해결됩니다. 따라서 Fast R-CNN에서는 각 RoI(영역)에 RoI Pooling을 수행하여 고정된 길이의 벡터로 변환시키게 됩니다.

RoI Pooling을 시각적으로 쉽게 설명하기위해 위 그림을 그려보았습니다. Selective Search로 나온 RoI (영역, 박스) 부분을 Feature Map에서 추출한 결과가 5x4, 5x2, 4x3 크기의 영역이라고 합시다. 기존에는 크기가 다르므로 FC Layer에 입력으로 사용하지 못하지만 이를 RoI Pooling을 수행하면 오른쪽과 같이 2x2의 동일한 크기로 변환할 수 있게 됩니다. RoI Pooling은 SPPNet에서 1개의 Pyramid를 적용한 것인데요. 우리는 고정 길이의 벡터(2x2) 크기를 먼저 정할 수 있고, 5x4가 들어오면 초록색 셀인 3x2 크기를 Max Pooling하여 하나의 셀로 만들고, 2x2 크기의 빨간색 셀을 Max Pooling하여 하나의 셀로 변환합니다. 이렇게하면 5x4, 5x2, 4x3와 같이 가변적인 크기가 입력으로 들어와도 고정 크기인 2x2로 변환할 수 있습니다. 이를 코드로 확인하시려면 직관적으로 구현해놓은 다음 링크를 확인하셔도 좋을 것 같습니다.
RoI Pooling을 통해 각각의 Region(Box)을 고정 크기의 벡터로 변환한 후, 각각의 벡터를 FC layer에 통과시켜 Classification과 Regression을 수행하여 결과물을 얻습니다.
Faster R-CNN
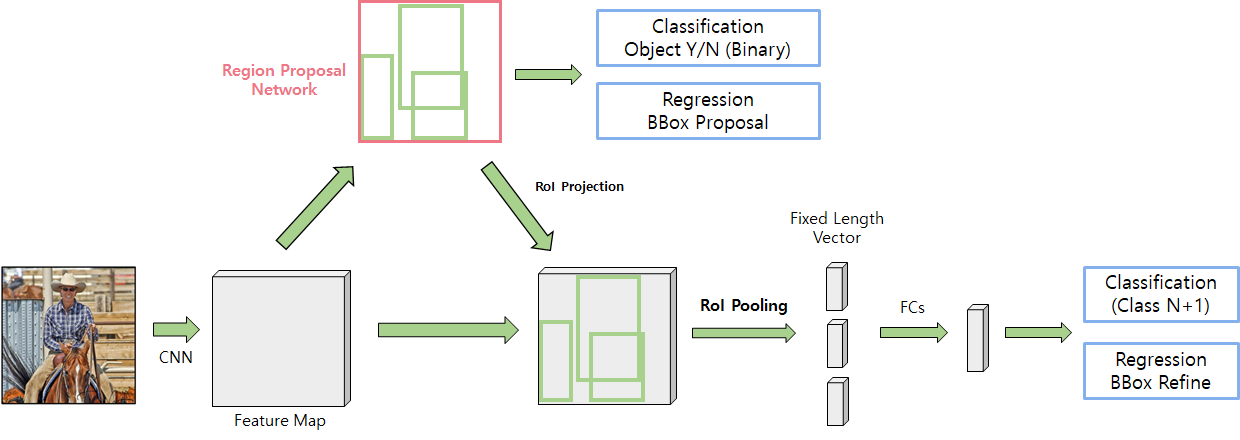
이전의 Fast R-CNN은 하나의 입력 이미지마다 2천 번의 CNN을 수행하던 것을 RoI Pooling으로 단 1번의 CNN을 통과시켜 엄청난 속도 개선을 이뤄냈습니다. 하지만 여전히 영역을 제안하기위해 Selective Search라는 알고리즘을 사용하는데, 이는 GPU 내에서 연산을 수행하는 것이 아닌 CPU에서 작동하기 때문에 병목이 발생하게 됩니다. 따라서, Faster R-CNN은 이러한 점을 해결하고자 영역을 제안(Region Proposal)하는 것도 CNN 내부에서 수행을 하여(=GPU를 이용가능) 네트워크를 빠르게 만들자는 아이디어에서 출발합니다.
먼저 전체 프로세스를 살펴보면 입력 이미지를 CNN에 통과시켜 Feature Map을 얻습니다. 그리고 해당 Feature Map을 Region Proposal Network의 입력으로 사용하여 초록색 Box 영역을 뽑아내게 됩니다. 그렇게 뽑아낸 영역을 기존 Feature Map에서 추출하여 해당 영역을 RoI Pooling을 수행하고, FC Layer를 통해 Classification과 Regression을 수행하게 됩니다. Fast R-CNN과 다른점은 영역을 제안하는데 RPN이라는 CNN 기반의 네트워크를 사용하여 1) GPU에서 동작할 수 있어 빠르다. 2) 전체 네트워크내에 포함되어 End-to-End 구조이다. 라는 장점이 있습니다.
Faster R-CNN의 핵심이라 할 수 있는 Region Proposal Network에 대해 조금 더 자세히 살펴보겠습니다.
Region Proposal Network (RPN)

앞서 RPN의 입력은 입력 이미지로부터 CNN을 통과한 Feature Map이라고 했습니다. 그렇다면 해당 Feature Map이 RPN에서 어떻게 Region을 추출하는지를 살펴보겠습니다. 위 그림처럼 7x7 크기의 Feature Map이 있다고 할 때, 3x3 크기의 Kernel 크기로 Sliding window 방식으로 모든 격자 셀마다 서로 다른 크기의 k개(논문에선 9개)의 Anchor Box를 정의해둡니다. 여기서 Anchor Box 크기는 9개로 정의해두기는 하지만, Anchor Box와 GT Box의 차이를 Regression으로 예측하므로 다양한 크기의 Predict Box가 나오게 됩니다.
따라서, Encoder로부터 (Channel, 7, 7)의 Feature Map을 3x3 Conv에 Padding을 1로 주어 (256, 7, 7) 크기로 만듭니다. 이후 물체가 존재하는지 하지 않는지를 예측하는 Classification을 수행하기 위해 1x1 Conv로 2(배경/전경) * 9(anchors) = 18 채널로 만들고, BBox의 좌표를 예측하는 Regression을 수행하기 위해 1x1 Conv로 4(x,y,x,h) * 9(anchors) = 36채널을 만들게 됩니다. 이를통해, 각 Grid(7x7) 별로 9개 Anchor의 Class와 좌표값 예측을 수행하게 됩니다.
Bounding Box Regression

출처 : https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html BBox를 Regression 하여 예측할 때는, 실제로 데이터셋은 BBox의 네 개의 모서리 좌표를 예측하는 것이 아니라 우리가 미리 정의한 Anchor Box와 Ground Truth BBox의 차이를 예측하도록 학습시키게 됩니다.
Loss Function

출처 : https://lilianweng.github.io/lil-log/2017/12/31/object-recognition-for-dummies-part-3.html Loss는 Classification과 Regression을 학습시키기 위해 Multi-task Loss를 사용합니다. Classification은 Cross Entropy를 사용하고 Regression은 Smooth L1 Loss를 사용합니다.
이상으로 R-CNN, Fast R-CNN, Faster R-CNN에 대한 요약을 마치겠습니다. 혹시 질문이나 잘못된 부분이 있다면 댓글로 편하게 말씀해주시면 감사하겠습니다.
** 아래는 RPN에서 Anchor Box와 학습 데이터셋을 구성하는 과정을 코드로 구현한 것을 살펴보면서 정리한 것이니 참고하시면 좋을 것 같습니다.
실제 학습 데이터셋 구성은 다음과 같은 Process를 통해 이루어집니다.
PASCAL VOC2012 기준 (GT정보를 담고있는 XML BBox 형태: Xmin,max, Ymin,max)
1. Label 추출
입력 : XML 파일 1개
출력 : Object 개수만큼의 class Label과 bbox(xmin, xmax, ymin, ymax) 정보
2. Anchor Box 생성 (x,y,w,h)
입력 : Feature Map size, RPN Kernel size, Anchor size, Anchor aspect Ratio
과정 :
1) Kernel size만큼 Feature Map Grid Cell을 돌면서 (x축 1씩 더해가고, x축으로 끝까지가면 y축 1더하고 x축은 처음으로 초기화)
2) Anchor 좌표가 Feature Map에서의 좌표이므로 이미지에서의 크기만큼 비율을 곱해줌
3) Anchor Size, Anchor aspect ratio 만큼 2중 For문 -> Feature map Grid에서 9개의 다른 크기의 Anchor Box 생성됨 (Shape: 9 x 4).
4) Total Anchor 개수(Feature Map크기가 7이었다면 9 * (7 - 3(Kernel size)**2 = 144개) 와 이미지 영역을 벗어나는지 여부 0/1로 Return
3. 실제 학습에 사용할 Anchor Box Sample 추출
1) 하나의 이미지에서 GT Box개수만큼 For문 j
2) Anchor 개수(144)만큼 For문 i - 다만 Anchor가 경계를 벗어나는 경우는 Continue
3) GT Box (j번째)와 Anchor Box(i번째)의 Area를 구하고, IOU를 계산
4) IOU가 0.7 이상이면 Positive Sample, 0.3이하이면 Negative Sample로 사용함.
5) 이 때, Positive인 경우 해당 Anchor의 Object 있음 값을 1로 둔다, Class Label 정보도 추출함.
그리고, Regression을 하기위해 GT와 Anchor Box의 차이로 변형
6) Negative인 경우는 Anchor의 Object 없음 값만 1로둠.
7) Pos와 Neg 사이인 경우 Anchor의 Object 있음/없음 값 모두 0으로 둠 (학습에서 배제)
4. Anchor Sampling
1) Pos, Neg Anchor Box를 정해진 개수만큼 샘플링
5. Generate Dataset
1) Batch 단위로 데이터셋 구성
2) 해당 Anchor 사용 여부(0/1) : (Batch, Anchor Sampling 수)
Anchor Object 여부 : (Batch, Anchor Sampling 수, 2) (dim=3에 0번째=1 객체있음, 1번째=1 객체없음)
BBox Regression 값 : (Batch, Anchor Sampling 수, 4)
Class Label : (Batch, Anchor Sampling 수, 20)