-
[논문 리뷰 및 코드구현] TABNET딥러닝 논문리뷰 및 코드리뷰 2020. 12. 6. 23:54
[Review] TABNET: Attentive Interpretable Tabular Learning (2019)
이번 포스팅은 Tabular(정형) 데이터에 적합한 딥러닝 모델이라 주장하는 TABNET 논문 리뷰를 해보겠습니다.
궁금한점이나 해석이 잘못된 부분이 있으면 언제든지 댓글로 말씀해주시면 감사하겠습니다.
먼저, 기존 딥러닝 모델들은 이미지, 텍스트, 음성 등 다양한 비정형 데이터 영역에서 매우 우수한 성능을 보여주었습니다. 그러나, 정형 데이터의 경우에는 최근까지도 Kaggle과 같은 여러 Competition에서 XGBoost, LightGBM, CatBoost와같은 Tree기반의 앙상블 모델들이 주로 사용되고 있습니다.
왜 Tabular 데이터에서는 기존 딥러닝 모델이 잘 작동하지 않을까요? 논문을 따라가며 천천히 설명해보겠습니다.
Introduction
저자들은 Tree기반의 앙상블 모델들이 딥러닝 모델보다 우수한 이유로 세 가지를 이야기합니다.
(1) their representation power for decision manifolds with approximately hyperplane boundaries that are commonly observed for tabular data.
일반적으로 Tabular data는 대략적인 Hyperplane(초평면) 경계를 가지는 Manifold라고 합니다. 부스팅 모델들은 이러한 Manifold에서 결정(decision)을 할 때, 더 효율적으로 작동한다고 합니다. 위 말을 간단하게 해석해보면, 정형 데이터의 포인트들이 어떤 차원(Manifold)상에서 위치하는 특성으로 인해 부스팅 모델의 결정기준이 더 적합하다는 것으로 해석하였습니다.
* 정형 데이터가 왜 초평면 경계를 가지는 Manifold인지는 모르겠지만, 제가 유추해 봤을 때 이미지의 경우는 하나의 사진에서 각 픽셀들(Feature)이 강한 Correlation을 가지는 특성이 있고, 텍스트나 음성의 경우에도 각 Feature가 Sequential하게 이어진다는 특성이 존재합니다. 반면에, 정형 데이터의 경우에는 데이터가 결측값, 다수의 0값, 또는 원핫인코딩과 같은 기법으로 인해 Sparse한 경우가 많기 때문에 Manifold 자체가 다른 것이 아닐까라고 생각하였습니다.
(2) decision tree-based approaches are easy to develop and fast to train.
Tree기반의 모델들이 학습이 빠르고 쉽게 개발할 수 있다고 합니다.
(3) They are highly-interpretable in their basic form (e.g. by tracking decision nodes and edges) and various interpretability techniques have been shown to be effective for their ensemble form.
Tree기반의 모델들은 높은 해석력을 가지고 있다는 장점이 있다고 합니다. Tree기반 모델의 특성 상 변수 중요도를 구할 수 있으므로 딥러닝 모델에 비해 상대적으로 해석이 용이합니다.
CNN or MLP may not be the best fit for tabular data decision manifolds due to being vastly overparametrized – the lack of appropriate inductive bias often causes them to fail to find robust solutions for tabular decision manifolds.
반면에, 딥러닝 모델은 지나치게 Overparametrized된다는 단점때문에 정형 데이터에 적합하지 않다고 합니다.
그럼에도 불구하고, 정형 데이터에 딥러닝 모델을 사용하는 것은 가치있다고 주장합니다.
(1) 훈련 데이터가 매우 많아지면, 계산 비용은 많이 들겠지만 성능은 더 높일 수 있음.
(2) Tabular 데이터와 이미지(텍스트) 등 다른 데이터 타입을 학습에 함께 사용할 수 있음. (Multi-modal Learning)
(3) Tree 기반에서 필수적인 Feature Engineering과 같은 단계를 크게 요구하지 않음.
(제 생각에는 어느정도 해결은 되겠지만 Tabular data에서 Feature Engineering은 여전히 중요할 것이라 생각됩니다)
(4) Streaming 데이터로부터의 학습이 용이함. Tree 기반의 모델들은 데이터의 분기를 통해 Global한 통계적 정보를 이용해야 하므로 스트리밍 학습은 어렵다는 큰 단점이 존재합니다. 반면 딥러닝 모델은 그러한 학습에 유연합니다.
(5) 딥러닝 End-to-End모델은 Domain adaptation, Generative modeling, Semi-supervised learning과 같은 가치있는 Application이 가능하다는 장점이 있음.
저자들은 위와 같은 딥러닝 모델의 이점들을 활용하기 위해 DNN 아키텍처를 재구성했다고 합니다.
저자들이 주장하는 Contribution은 다음과 같습니다.
(1) TabNet은 Feature의 전처리없이 raw한 데이터를 입력으로 사용할 수 있고, Gradient-descent 기반 최적화를 사용하여 End-to-End learning을 가능하게 하였음.
(2) 성능과 해석력을 향상시키기 위하여, TabNet은 Sequential attention mechanism을 사용하여 각 의사결정에서 어떤 feature를 사용할지를 선택함. 이러한 Feature selection은 instance-wise하게 입력 각각마다 다르게 수행됨.
(3) 여러 데이터셋에서 기존의 정형 분류,회귀 모델들보다 성능의 우수성을 가짐. 그리고 해석력의 관점에서 입력 Feature의 중요도와 Feature들이 어떻게 결합되었는지를 시각화한 local한 해석력과, 학습된 모델에서 각 입력 Feature들이 얼마나 자주 결합되었는지의 Global한 해석력을 제시함.
Related Work
Tree-based learning
기존 Tree 기반 모델들은 모델의 분산을 줄이면서 성능의 향상을 이끌어내었습니다. 대표적으로 앙상블 기법을 사용한 모델로는 Random Forest, XGBoost, LightGBM 등이 있습니다.
Integration of neural networks into decision trees
기존 연구들
1) 인공 신경망의 Block을 의사결정나무로 표현하면 중복으로 인해 비효율적인 학습이 됨.
2) Soft (neural) decision tree는 미분가능한 결정함수를 사용하였으나, 자동적인 Feature selection 기능을 상실하게 됨.
3) Feature들의 결합과 모델의 복잡도를 줄이는 방법이 제안되었으나, 성능 향상이 제한적이고 해석 가능성을 고려하지 않음.
Methods

TabNet의 전반적인 구조는 위의 그림과 같습니다. 전체적인 Architecture는 입력부분과 Step1~N으로 나누어져 있고, 각 단계마다 Feature transformer와 Attentive transformer, Feature masking으로 구성되어 있습니다. 그리고, Split block은 Feature transformer로부터 나온 representation을 두 개로 나누어, 하나는 ReLU를 태워 최종 아웃풋으로 보내주고, 나머지 하나는 다음 Attentive transformer로 넘겨줍니다. 그 후, Feature를 selection하는 Mask block은 각 Step에서 Feature가 작동하는 것에 대한 Insight를 제공할 수 있고, Agg(regate) Block을 통해 궁극적으로는 어떤 Feature가 중요한지에 대한 것을 알 수 있습니다.
먼저 모델의 입력 부분을 살펴보겠습니다. Tabular 데이터는 Numerical과 Categorical Feature로 이루어져 있습니다. Numerical 같은 경우는 상관없으나 Categorical 변수는 기본적으로 원핫인코딩 등의 처리를 해주어야 합니다. 그러나, 해당 모델에서는 임베딩 레이어를 구성하여 Categorical변수를 임베딩하고 임베딩 레이어 역시 학습 레이어로 구성합니다.
그리고 입력 Features 부분을 보시면 BatchNorm레이어가 존재하는 것을 볼 수 있습니다. Tabular 데이터는 보통 Min-Max or Standard scaling을 수행하고 입력으로 사용하는데, 그러한 Normalization을 BatchNorm 레이어를 사용하여 대체하였다고 합니다. 그렇게 Normalization된 입력은 Feature transformer block으로 들어가게 됩니다.

Feature transformer block은 다음과 같이 구성되어 있습니다. FC-BN-GLU를 4번 반복되어 있는 구조를 지니고 있습니다. 그 중 앞 2개의 Block은 모든 decision step에서 공유되고, 뒤 2개의 Block은 해당 decision step에서만 사용됩니다. GLU는 Gated Linear Unit의 약자로 Language Modeling with Gated Convolutional Networks 에서 소개된 구조로, 아래와 같이 어떤 Linear Mapping을 통해 나온 결과물을 정확히 반(A, B)으로 나누어 A는 Residual connection, B는 Sigmoid function을 거친 후 Element-wise로 계산한 것입니다.
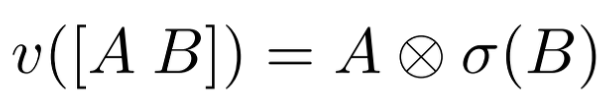
GLU Notation
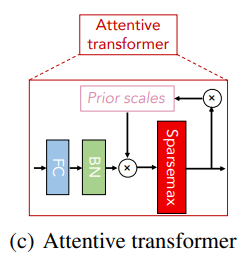
Attentive transformer block은 위의 그림처럼 구성되어 있습니다. Prior scale은 이전 decision step들에서 각 feature가 얼마나 많이 사용되었는지를 집계(Agg block)한 정보입니다. 이전 단계들의 중요한 Feature를 selection하기 위해 Sparse Mask를 학습해야합니다. 또한, Masking을 통해 decision step 과정에서 학습에 큰 영향을 미치지않는 변수들은 영향력을 줄여야 합니다. 그러한 Mask를 구하기 위해 Attentive transformer를 사용합니다. 해당 Mask를 구하는 Notation은 다음과 같습니다.


i번째 Mask는 M[i]는 Sparsemax라는 normalization을 수행합니다. 이는 각 decision step에서 가장 두드러진 Feature를 선택할 수 있는 기법입니다. P[i]는 (감마-이전 마스크)들의 곱으로 표현되고, 이는 이전 decision step로부터 처리된 Feature(a[i-1])과 Mask들의 영향을 고려하여 새로운 Mask를 만들겠다는 것입니다. 감마는 relaxation parameter로 감마가 1인 경우 Feature가 하나의 decision step에서만 사용되도록 강제하고, 감마가 커질수록 여러 decision step에서 사용되도록 하는 Hyper-parameter입니다.
* Sparsemax는 Softmax의 sparse한 버전으로, Sparse한 데이터셋에 적용했을 때, 좋은 성능을 보인 normalization 기법이라고 합니다. 해당 블로그에서 약간의 예시로 설명을 하고있으니 살펴보시면 좋을 것 같습니다.
Experiments
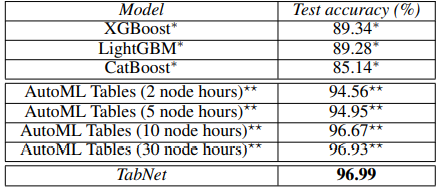
위 표는 여러 부스팅 모델과의 성능을 비교한 것입니다. AutoML을 수행한 모델들보다 성능이 우수한 것을 확인할 수 있습니다.

Feature importance masks 위는 TabNet의 저자들이 주장하는 해석력에 관한 그림입니다. Syn6 dataset에 대해서 학습할 때, 각 decision step 별로 어떤 Feature들이 중요하게 사용되었는지에 대한 시각화입니다. M[1], 즉 첫 번째 decision step에서는 4, 5번째 Feature들이 중요하게 사용되었고, 두 번째에서는 7번째, 11번째 (컬럼 위치는 정확하지 않을 수 있습니다) 변수가 사용된 것을 확인할 수 있습니다.
이처럼, 각 단계에서 어떤 변수들이 주로 사용되었는지를 해석할 수 있고, 이 부분이 Tree 기반의 모델들이 분기를 해가면서 Feature importance를 구한 것과 유사한 부분이라고 생각되었습니다. 뿐만 아니라, Sequential attention mechanism 부분이 의미있는 Feature의 subset을 선택할 수 있게하고, 또 다음 decision step으로 전달되는 과정이 부스팅 모델들이 잔차를 줄여나가는 Sequential한 부분과 유사하다고 느껴졌습니다.
TabNet 코드구현
1. Import Library
import os import numpy as np import pandas as pd from sklearn.metrics import roc_auc_score from sklearn.preprocessing import LabelEncoder from matplotlib import pyplot as plt import torch import torch.nn as nn from pytorch_tabnet.tab_model import TabNetClassifier먼저, Pytorch tabnet을 설치한 후 라이브러리를 불러옵니다. (pip install pytorch-tabnet)
2. Data load
train = pd.read_csv('../data/census-income.data', header=None) target = 41 # 41번째 컬럼 if "Set" not in train.columns: train["Set"] = np.random.choice(["train", "valid", "test"], p =[.8, .1, .1], size=(train.shape[0],)) train_indices = train[train.Set=="train"].index valid_indices = train[train.Set=="valid"].index test_indices = train[train.Set=="test"].index이번, 리뷰에서 사용한 데이터셋은 해당 논문에서도 벤치마크 셋으로 사용한 census-income 데이터셋입니다.
해당 데이터는 소득(income)이 50k를 초과하는지, 아닌지에 대한 이진 분류 데이터셋입니다. 41번째 컬럼이 소득에 해당하는 Target입니다. 데이터 셋이 나뉘어져 있지 않으므로, Train / Valid / Test set으로 구성하기 위해 80%, 10%, 10%로 나누어줍니다.
3. Data Preprocessing
nunique = train.nunique() types = train.dtypes categorical_columns = [] categorical_dims = {} for col in train.columns: if types[col] == 'object' or nunique[col] < 200: print(col, train[col].nunique()) l_enc = LabelEncoder() train[col] = train[col].fillna("VV_likely") train[col] = l_enc.fit_transform(train[col].values) categorical_columns.append(col) categorical_dims[col] = len(l_enc.classes_) else: train.fillna(train.loc[train_indices, col].mean(), inplace=True) # Categorical Embedding을 위해 Categorical 변수의 차원과 idxs를 담음. unused_feat = ['Set'] features = [ col for col in train.columns if col not in unused_feat+[target]] cat_idxs = [ i for i, f in enumerate(features) if f in categorical_columns] cat_dims = [ categorical_dims[f] for i, f in enumerate(features) if f in categorical_columns] X_train = train[features].values[train_indices] y_train = train[target].values[train_indices] X_valid = train[features].values[valid_indices] y_valid = train[target].values[valid_indices] X_test = train[features].values[test_indices] y_test = train[target].values[test_indices]간단한 전처리로 컬럼의 unique한 값이 200개 이하이면 Categorical 변수로 변환하고, 200개 이상인 경우 Numerical로 판단하여 Null value를 평균값으로 대체해줍니다.
그리고 논문리뷰에서 설명했듯이 TabNet은 입력으로 Categorical변수를 Embedding 하기 때문에, Categorical 변수라는 것을 지정해주어야 합니다. 따라서, cat_idxs와 cat_dims를 저장해둡니다.
4. Define the Model
clf = TabNetClassifier(cat_idxs=cat_idxs, cat_dims=cat_dims, cat_emb_dim=10, optimizer_fn=torch.optim.Adam, optimizer_params=dict(lr=1e-2), scheduler_params={"step_size":50, "gamma":0.9}, scheduler_fn=torch.optim.lr_scheduler.StepLR, mask_type='sparsemax' # "sparsemax", entmax )이후 TabNet의 Classifier를 정의해줍니다. cat_idxs는 카테고리 변수의 위치를 알려주는 것이고, cat_dims는 각 카테고리 변수의 Cardinality를 말합니다. cat_emb_dim은 카테고리 변수의 임베딩 사이즈를 의미하고, 나머지 optimizer, scheduler는 딥러닝 모델처럼 유연하게 설정해주면 됩니다. 그리고 mask type의 경우 sparsemax를 사용하였습니다.
(entmax라는 것도 옵션으로 존재합니다만, 해당 기능은 정확히 파악하지 못하였습니다)
5. Train/Valid
max_epochs = 15 clf.fit( X_train=X_train, y_train=y_train, eval_set=[(X_train, y_train), (X_valid, y_valid)], eval_name=['train', 'valid'], eval_metric=['auc'], max_epochs=max_epochs , patience=20, batch_size=1024, virtual_batch_size=128, num_workers=0, weights=1, drop_last=False, )이후 Epoch을 설정하고, metric으로 auc를 설정해줍니다. 위를 토대로 학습한 결과는 다음과 같습니다.

preds = clf.predict_proba(X_test) test_auc = roc_auc_score(y_score=preds[:,1], y_true=y_test)시간 관계상 15Epoch을 수행하였고, 최종적으로 Test score는 0.9475로 나왔습니다.
explain_matrix, masks = clf.explain(X_test) fig, axs = plt.subplots(1, 3, figsize=(20,20)) for i in range(3): axs[i].imshow(masks[i][:50]) axs[i].set_title(f"mask {i}")최종적으로 나온 결과물을 바탕으로 TabNet에서 주장하는 해석력을 시각화 해보았습니다. explain함수를 사용하면 해당 결과물을 확인할 수 있습니다. explain_matrix는 (Test set 수, 변수개수)로 이루어져 있어, 각 샘플별로 변수들의 영향력을 확인할 수 있습니다.
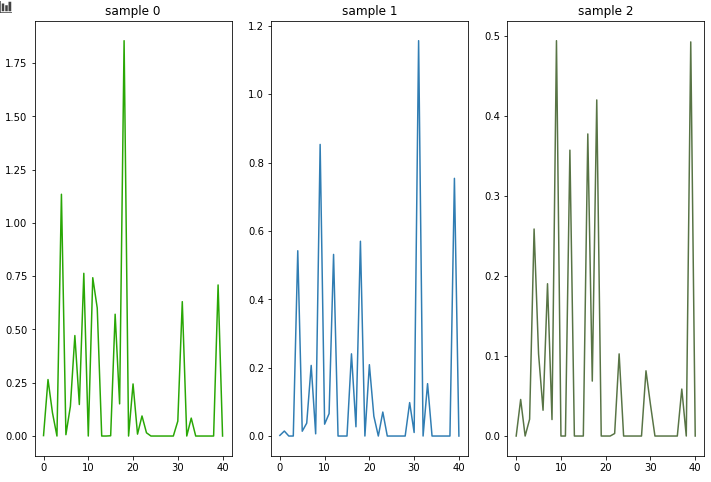
샘플0,1,2의 변수 영향력 (Local interpretable) 0번째 샘플의 경우는 19번째 변수가 가장 많은 영향을 미쳤고, 1번 샘플은 31번째가 영향을 많이 미친것을 확인할 수 있습니다.
그리고, 샘플 전체에 대해 어떤 변수들이 중요한지에 대한 Mask를 시각화하면 아래 그림과 같습니다.

Global interpretable 마지막으로, 사실 해당 논문은 2020 ICLR에 제출했다가 reject 되었습니다... reject된 것도 놀라운데 저자가 Google cloud AI 연구원들이란 것에 한 번 더 놀랬던 논문이었습니다. 왜 리젝이 되었는지에 대한 이유로 오픈리뷰에 리뷰어가 코멘트한 부분이 길게 작성되어 있습니다. 간단하게 요약하면 아이디어에 대한 논리는 적절하나, 해당 논리를 뒷받침할 실험이 매우 부족하다는 것이 이유였습니다. 논문을 봐도 다른 XGBoost, LGBM, CatBoost 등의 모델과 다양한 데이터셋에서 실험을 한 부분이 부족해 보였습니다. 다만, 며칠 전 종료된 MoA라는 캐글 Competition에서 Leaderboard의 상위 랭커들이 대부분 TABNET을 Baseline으로 사용하였습니다. 해당 논문이 실험적인 입증이 부족하여 리젝은 되었지만, 아이디어의 논리적인 구성이 괜찮았고, 캐글 컴페티션에서 사용되는 모델인만큼 성능 면에서도 입증이 된 괜찮은 모델 구조를 제시하였다고 생각합니다.