-
[논문리뷰] EGNet: Edge Guidance Network for Salient Object DetectionImage Segmentation 2020. 12. 24. 20:53
EGNet: Edge Guidance Network for Salient Object Detection, ICCV 2019
먼저, Salient object detection(돌출 객체 검출) Task는 이미지에서 가장 돌출된 부분을 검출 해내는 것으로, 일반적인 Semanctic Segmentation보다 더 Challenge합니다. 이름에서 보듯이 Object Detection이 들어가서 오해하실 수 있지만 일반적인 Semantic Segmentation Task에서 중요한 부분만을 Segmentation하는 Task라고 생각하시면 될 것 같습니다.
Abstract
기존 FCN-based 방법론들은 객체의 경계면이 Coarse하다는 문제점이 존재합니다.
EGNet은 이를 해결하기 위해 두 가지의 상호 보완적인 정보를 결합하는 3가지의 단계를 제안합니다.
1) 점진적으로 융합하는 방식으로 object의 features를 추출함.
2) Local edge 정보와 global한 위치 정보를 결합함.
3) 이러한 상호보완적인 Features를 충분히 레버리지함.
즉, Salient Edge features의 풍부한 Edge 정보와 위치 정보를 융합하고,
융합된 피처는 경계를 더 정확하게 표현하면서 위치 역시 잘 찾아낼 수 있다는 아이디어입니다.
Introduction
Receptive Field를 증가시킬 수 있는 네트워크의 등장으로 객체의 위치를 더 정확하게 잡아내게 되었습니다.
그러나, 공간적인 coherence(통일, 결합의 긴밀성)이 고려되지는 않았다고 합니다. (pixel-wise 방법들)
Bidrectional이나 Recursive 방법들은 고차원 Feature와 로컬한 정보를 함께 보완하였으나 여전히 경계면을 명시적으로 모델링하지는 않았습니다.
즉, Segment를 할 때 중요한 Edge 정보와 중요한 객체의 정보사이의 상호보완성에 대해서는 주목하지 않았다고 언급합니다. Superpixel이나 CRF같은 전처리, 후처리 방법론들은 객체의 경계를 보존하였으나 추론 시의 속도가 느리다는 단점이 있습니다. 따라서, 저자들은 Edge와 Object 두 Feature를 독립적으로 추출하는 2개의 Module과, 상호작용이 잘 일어나도록 융합시켜주는 One-to-One guidance module을 제안하였습니다. 이를통해 Edge의 quality뿐만 아니라 더 정확한 localization을 할 수 있게 되었다고 합니다.
저자들이 주장하는 Contribution은 다음과 같습니다.
1) Segmentation하고자 하는 객체의 경계를 보존하기 위해서, 중요 객체의 정보와 중요 Edge 정보를 명시적으로 Modeling한 네트워크이다. 그리고, 중요 Edge features는 localization에도 도움이 됨.
2) 상호보완적인 두 Task를 함께 Optimize함.
3) 15개의 방법론과 6개의 데이터셋을 실험함.
Methods
1. Motivation
Pixel-wise 기반 방법이 Region 기반 방법보다 우수하나, 공간적인 결합의 긴밀성(Coherence)가 무시된다고 합니다. 그 결과 객체의 경계면을 잘 찾아내지 못하게 됩니다. 이를 해결하기 위해 Multi-scale의 정보를 융합하거나, CRF같은 후처리 방법을 제시합니다. Edge를 둘러싼 위치의 Gradient에 영향을 주는 방법으로 IOU Loss가 제안되기도 하였습니다. 그러나, Salient edge detection과 salient object detection간의 상호보완성에 집중한 연구는 없었다고 합니다.
따라서, 중요 객체의 Edge부분의 detection을 잘하면 Segmentation과 localization 모두에 도움이 된다고 주장합니다.
2. Complementary information modeling

VGG Network를 Backbone으로 사용하였고, Conv1-2 Feature map은 입력과 너무 가까워 Receptive Field가 너무 작으므로, 추가적으로 사용하지 않았습니다. 따라서, Conv2-2, 3-3, 4-3, 5-3, 6-3을 C(2), C(3), C(4), C(5), C(6)로 정의하고, C(2)에서는 Edge feature를 추출하고 나머지 C(3)~C(6)에서는 Object의 feature를 추출하였습니다.
(1) PSFEM (Progressive Salient Object Features Extraction Module)
풍부한 Context Feature를 얻기위해 UNet구조를 사용하여 multi-resolution의 feature들을 생성하였습니다. UNet과 다른점은 더 Robust한 객체의 features를 얻기위해서 Backbone의 각 Block을 통과한 Feature map을 Side path로 보내어 3개의 Conv layer를 추가하였습니다. 즉, Conv2-2에서 나온 Feature에 (Convolution-ReLU)를 3번 반복한 것입니다. 마찬가지로 다른 Conv3-3, 4-3, 5-3, 6-3도 각각 3번 반복하여 Feature를 추출하였고, 각 Side output의 Deep Supervision을 계산하기 위해 Transition layer(D)를 사용하여 채널을 1로 줄여주었습니다. (Mask와 Loss계산을 위한 중간층 Feature map의 Representation)
* 착각할 수 있는 부분: 백본 Layer상에서 추가적인 Conv를 사용한 것이 아닌, 그림에서 노란색 Conv로 되어있는 것처럼 옆으로 Feature map을 따로 보내주어 사용한 것.

T1(First Conv-ReLU), T2(Second Conv-ReLU), T3(Third Conv-ReLU), D(Transition Layer) 위 표는 각 Side에서 사용한 Conv size와 Padding, 그리고 Channel을 표현하고 있습니다. 깊은 레이어로 갈수록 Kernel size를 키워주는 특징이 있습니다. 이를 통해 Robust한 객체의 Features를 얻을 수 있다고 얘기합니다.
(2) NLSEM (Non-local salient edge features extraction)
해당 모듈은 중요한 Edge features를 추출하고, 중요한 Edge정보를 모델링하는 기능을 합니다.
Conv2-2 피처맵은 Local한 Edge 정보를 충분히 가지고 있습니다. 그러나, 중요 객체의 Edge 정보만을 가지고 있는 것이 아니기 때문에 Local한 정보만 가지고는 불충분합니다. (즉, Segmentation에 필요하지 않은 다른 객체들의 Edge정보도 가지고 있기 때문에) 따라서, High-level의 semantic한 정보(객체의 위치정보)가 필요합니다. (객체의 위치정보와 Local한 Edge정보가 겹쳐지는 영역이 우리가 segmentation하는 영역일 것이기 때문에)
일반적인 UNet 구조에서도 top level(깊은 레이어)에서의 Receptive Field가 가장 크기 때문에, 특정 객체의 위치정보가 가장 정확합니다. 따라서, Top-down location propagation을 통해서 Conv2-2 Feature map(Edge 정보)에 Conv6-3 Feature map(정확한 위치정보)의 정보를 더해줌으로써 중요하지 않은 부분(Non-local salient)의 Edge 정보들은 제지하는 효과를 내었습니다. 정확하게는 Conv6-3을 3개의 Conv-ReLU로 향상시킨 Feature map(F6)을 Transition Layer(Conv-ReLU)로 채널을 적당히 줄여주고 (512->64), Conv2-2의 Feature map 사이즈로 Bilinear Upsampling을 한 뒤 Element-wise로 더해줍니다. 이렇게 융합된 Feature map은 Context가 가장 강한 위치정보와 풍부한 Edge정보들이 결합되어, 중요한 부분의 Edge정보만 남아있는 Feature라고 할 수 있습니다.

Edge Guided Feature : Conv2-2 Feature와 Conv6-3 Feature Fusion 이후, 위의 결합된 Edge Feature(C2 bar)를 Conv-ReLU 3Block을 태워 향상시킨 Feature map을 F_E로 표현합니다.
그리고, Conv6-3을 Conv-ReLU 3Block 반복으로 향상된 Feature map을 hat{F6} 이라 하고, hat{F3~5}는 아래 수식과 같이 표현됩니다.

hat{F5}는 hat{F6}의 feature map을 Transition layer로 채널을 줄여주고, Upsampling을 한 뒤, 한 층 위의 Feature map C(5)와 더해준 뒤 Conv, ReLU를 통과한 것입니다. 기존 UNet은 Upsampling을 한 뒤 채널 방향으로 Concat하고 Conv layer로 채널을 줄여주는데, 여기선 Element-wise로 더해주었다는 차이점이 있습니다.
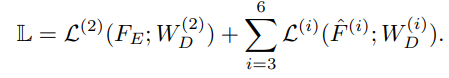
따라서, 해당 Supervision Loss는 Edge feature인 F_E를 Transition layer(W_D)로 1채널로 압축한 것과, Object feature인 hat{F6, F5, F4, F3}를 Transition layer(W_D)로 1채널로 압축한 것을 Prediction으로 사용합니다.
(3) O2OGM (One to One Guidance Module)
Edge feature와 Object feature의 상호보완적인 결합으로 얻어진 F_E는 중요한 객체의 Edge정보를 충분히 담고있을 것입니다. 따라서, 이 Feature를 Object feature들이 segmentation과 localization을 더 잘 할 수있도록 Guide를 해주는 역할을 하도록 하는것이 목표입니다. 간단하게는 F_E와 hat{F3}이 결합되는 것입니다. 이는 다양한 크기를 가진 중요 객체 features를 더 효율적으로 잡아낼 수 있게 도와줍니다.
그러나, Edge feature와 Multi resolution의 object features를 혼합하는 것은 다음과 같은 문제가 존재합니다.
모델의 구조가 Down(깊은 Layer)에서 Top(얕은 Layer)으로 구성되어 있기 때문에, 상호보완으로 얻어진 Edge features(FE)는 Encoder 레어이를 다 통과한 후에 얻어지기 때문에, 각 Resolution의 object feature에 더해질 수가 없습니다. 따라서, hat{F6}이 hat{F5}에 더해지는 방법은 Edge features가 간접적으로 더해지는 것입니다. 이러한 과정에서 Edge가 희석되어지게 되므로 Edge를 더해주는 효과가 줄어들게 됩니다.
따라서, 저자들은 sub-side path를 만들어 Upsampling되며 Object Feature map끼리 혼합되는 부분은 그대로 둔채, sub-side를 만들어 중요한 부분의 Edge 정보를 가진 F_E를 각 sub-side feature와 직접적으로 혼합시켜주었다고 합니다. (그림의 FF Block)
FF Block은 아래의 수식과 같이, 각 3~6 layer의 side path를 Transition으로 채널을 줄이고, F_E feature map 크기만큼 Upsampling한 후 F_E를 Element-wise로 더해줍니다.

이후 PSFEM 모듈에서와 같이 Feature를 향상시켜주기 위해 Conv-ReLU Block을 통과한 후 Transition layer로 1채널로 줄여 Prediction map(Deep supervision)으로 사용합니다.

마찬가지로 Deep Supervision Loss로 G(3~6) Map을 사용하고, 최종 Prediction Map은 G(3~6)을 평균낸 것을 사용합니다.
최종 Loss는 이전의 L= F_E + Object Feature(3~6)과 L' = Final map + sub side Features(3~6)을 더한 L + L'을 사용합니다. 따라서 최종 Loss를 계산하는 Map은 10개이다.
Experiments
Implementation Details
Weight 초기화= normal (시그마=0.01, bias=0)
Learning rate = 5e-5
Weight decay = 0.0005
momentum = 0.9,
각 Side output의 Weight = 1로 동일하게 둠.
학습동안 Validation Data를 사용하지 않음.
24Epoch을 학습하엿고, 15에폭후에 LR을 1/10로 낮춤.

EGNet은 Salient object detection에서 주로 사용되는 6개의 벤치마크 데이터셋과 3개의 평가지표에 대하여, 기존의 방법론들보다 우수한 성능을 보여주었습니다. 빨간색으로 색칠된 부분을 살펴보시면 기존방법들보다 성능향상이 확 일어난것을 확인하실 수 있습니다.
최종요약
1) UNet 기반의 Multi resolution의 salient object features를 추출
2) 중요한 객체의 Edge feature만을 뽑기위해 Local edge정보와 global location정보를 융합
3) 그렇게 뽑힌 두 정보를 상호보완하여 얻어진 중요 객체의 Edge feature를 O2OGM을 통해 object feature의 Edge를 풍부하게 만들어 성능을 높임
돌출된 객체의 Edge정보를 이용할 수 있는 방법으로 얕은 레이어의 Edge Feature와 깊은 레이어 Feature의 위치정보를 함께 결합한다는 것이 가장 큰 아이디어였고, 이를 논리적으로 풀어나가는 좋은 논문이었다고 생각합니다. 보면서 궁금한 점이나 잘못된 점이 있었다면 언제든 댓글 남겨주시면 감사하겠습니다.
'Image Segmentation' 카테고리의 다른 글
[논문 리뷰 및 코드구현] Simple Does It: Weakly Supervised Instance and Semantic Segmentation (2) 2020.12.27 [논문리뷰] BASNet (Boundary-Aware Salient Object Detection) (0) 2020.12.11 [논문 리뷰 및 코드구현] UNet++ (Nested UNet) (9) 2020.10.10