[논문리뷰] BASNet (Boundary-Aware Salient Object Detection)
Boundary-Aware Salient Object Detection CVPR 2019
Introduction
먼저, Salient object detection(돌출 객체 검출) Task는 이미지에서 가장 돌출된 부분을 검출 해내는 것으로, 일반적인 Semanctic Segmentation보다 더 Challenge합니다. 이름에서 보듯이 Object Detection이 들어가서 오해하실 수 있지만 일반적인 Semantic Segmentation Task에서 중요한 부분만을 Segmentation하는 Task라고 생각하시면 될 것 같습니다.
돌출 객체를 정확하게 분할하기 위해서는 전체 이미지에서 Global한 정보를 이해할 수 있어야하고, 객체의 디테일한 구조 역시도 알수 있도록 해야합니다. 이러한 문제를 해결하기위해 본 논문은 2가지 방법을 제안합니다.
(1) 더 정확한 Salient Object 분할을 위해 Refinement Module을 제안합니다. 인코더와 디코더 구조를 통해 생성된 예측 맵은 Ground Truth에 비해 정확한 분할이 아닌 영역 또는 경계면(boundary)이 거칠(Coarse)기 때문에, 이를 정제(Refine)해주는 모듈을 추가하여 더 정확한 맵을 예측합니다.
(2) Saliency map을 더 확실하게(high confidence=높은 확률값) 예측하고 경계(Boundary)를 더 Clear하게 분할해내기 위해서 BCE + SSIM + IOU Loss를 합친 Hybrid loss를 제안합니다. 이는 Pixel, Patch, Map 3개의 Level을 고려한 것이라고 합니다. BCE Loss는 경계면을 예측할 때 Low confidence를 가지는 문제점이 있고, IOU, Dice Loss는 학습시 Bias 문제를 해결하지만 구체적인 구조를 고려하지 못한다는 단점이 있으므로 이러한 점을 해결할 수 있다고 합니다.
Methods

(1) Predict Module
먼저 위 그림의 파란색 부분인 Predict Module구조부터 살펴보겠습니다.
기존 UNet, SegNet과 마찬가지로 인코더 디코더 기반의 구조를 사용하였습니다. 이는 high level의 global context와 low level의 detail한 정보를 함께 사용할 수 있다는 장점이 있습니다. 그리고, 오버피팅을 피하기 위해 디코더 각 레이어의 Feature Map을 Deep Supervision으로 사용했습니다. (이는 중간 층의 Representation을 Ground Truth와 Loss를 학습함으로써 중간층의 피처도 GT에 가까워지도록 하는 효과를 줍니다.)
Detail한 구현으로는 인코더 초반 4개의 블락은 ResNet-34구조를 사용하였고, 기존 ResNet에서는 첫 input layer의 7x7 Conv와 stride2를 사용하는 반면에 본 구조에서는 channel64, 3x3Conv와 stride1을 사용하였습니다. 그리고 input layer이후에 Pooling역시 사용하지 않았습니다. 기존 Resnet-34는 Input layer를 거치면 1/4이 되지만, 본 구조에서는 Input layer를 거쳐도 Resolution이 원본과 같게 됩니다. 이는 초기 Layer에서 High Resolution을 가지게 되지만, Receptive Field가 감소하게된다는 점이 있습니다. 따라서, 기존의 Resnet-34와 Receptive Field를 같게 만들어주기 위해, 4개의 블락뒤에 추가적으로 2개의 블락을 사용하였고, 각 블락은 3개의 Max pooling & 512채널의 Res-block으로 이루어져있습니다. 그리고 Global한 정보를 잘 추출하기위해 인코더와 디코더 사이의 Bridge Layer에 3개의 Dilated conv(d=2) layer를 사용하였습니다. 디코더의 구조도 인코더와 유사하게 각 블락마다 3개의 Conv-BN-ReLU를 취해주었습니다. 그리고 Upsampling을 수행하고 인코더의 Skip connection과 Channel-wise로 concat을 하였습니다. 최종적으로, 디코더 레이어 6개와 마지막 Output, 총 7개를 Deep supervision으로 사용하였습니다.
(2) Refine Module (RRM, Residual Refinement Module)
다음으로는 Refine Module에 대해 살펴보겠습니다. 기존에도 Refine Module은 다른 논문에서 제안된 적이 있습니다.
아래 그림과 같이 기존에도 RRM_LC, RRM_MS가 존재하였는데요. 두 모듈모두 부족한 점이 있다고 언급하고 있습니다.
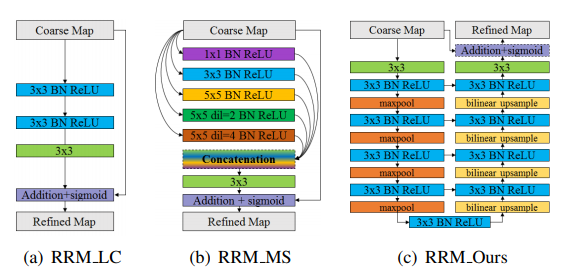
(a)RRM_Local Boundary같은 경우는 Receptive field가 부족하고, (b)RRM_Multi-scale 같은 경우는 Pooling으로 인한 디테일의 손실을 막기위해 Dilated conv를 썼으나, 깊이가 얕아 Refine을 위한 High level의 정보를 포착하기가 어렵다는 단점이 존재합니다. 따라서, 영역과 경계를 함께 보완하기 위해, Encoder-Decoder 구조를 활용하여, 심플하지만 효과적인 구조를 만들었습니다. Predict Module과의 차이점은 6개의 블락대신 4개의 블락을 사용했고, 각 층마다 오직 하나의 Conv(64channel, 3x3)를 사용하였습니다.
(3) Hybrid Loss
해당 논문에서는 high quality의 영역을 분할하고 명확한 경계를 얻기위해 BCE + SSIM + IOU를 합한 Hybrid Loss를 사용하였다고 합니다. 아래 그림은 각 Loss가 가지는 효과를 시각화한 것입니다. (bi : BCE+IOU, bs : BCE + SSIM, bsi : All)

BCE는 Loss는 일반적으로 Classification에서 주로 사용되고, Segmentation에서도 각 픽셀별로 Mask(Label)과 예측(Predict)를 계산합니다. 따라서 Pixel-wise이고, 이는 주변 픽셀들의 Label을 고려하지 않고 계산됩니다. 그리고, 전경(Foreground)와 배경(Background) 픽셀을 동일한 가중치를 부여합니다. 그러므로 모든 픽셀에 대해서 수렴을 하도록 도와줍니다.
SSIM은 일반적으로 두 이미지 복원 분야에서 품질을 정량적으로 평가할 때 사용하는 지표입니다. Structural similarity의 약자이며, 이미지의 구조적인 정보를 반영하여 사람의 지각 능력과 비슷하게 바라볼 수 있도록 하는 평가지표입니다.
SSIM은 Patch-level이며, 각 픽셀의 주변 영역의(Local) 픽셀을 고려하고, 경계 영역에 더 높은 가중치를 할당하는 효과를 가져옵니다. 따라서, 경계면 주변으로 높은 Loss를 주게되고, 경계부분의 최적화가 잘 이루어지게 됩니다.
그리고, 배경부분의 예측은 확률을 0에 가깝게 만들어주어 더 깔끔하게 예측이 됩니다.
IOU(Intersection over Union)으로 Object detection이나 Segmentation에서 주로 쓰이는 평가지표입니다. 해당 논문에서 IOU Loss는 Map-level이라고 합니다. IOU loss에 대한 설명은 다른 Paper에서도 많이 있으니 관심있으면 찾아보시면 될 것 같습니다.
따라서, 이 세 Loss를 결합하여 BCE는 모든 픽셀에 Smooth gradient를 주고 (학습이 Smooth하게 된다는 것을 의미하는 것 같습니다), IOU는 Foreground(전경, 객체)에 포커스를 맞출 수 있게하고, SSIM은 경계에 더 큰 Loss를 부여함으로써 원본 이미지의 구조를 예측하는데에 도움이 된다고 합니다.
Experimental Results
Implementation detail
Resize(256x256) & Random Crop(224x224)
Adam (lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0)
No validation set.
Training loss가 수렴할때까지 400k iterations (학습에 125시간... 엄청 오래걸린다는 단점이 있네요)
Batch size: 8