[논문 리뷰] Student Customized Knowledge Distillation: Bridging the Gap Between Student and Teacher
이번 포스팅은 2021 ICCV에서 발표된 Student Customized Knowledge Distillation: Bridging the Gap Between Student and Teacher 논문을 리뷰해보려고 합니다. 지식 증류(Knowledge distillation)에서 보편적인 생각 중 하나는 "더 좋은 성능을 지니는 교사 모델일수록 학생 네트워크가 더 좋은 성능 향상이 일어난다" 입니다. 하지만 이러한 직관과는 반대로 더 좋은 성능의 교사라고 해서 더 좋은 학생이 만들어지지는 않는다고 기존 연구들에서 실험적으로 증명되어 왔습니다. 저자들은 이러한 결과가 두 네트워크 간의 capacity mismatch 때문이라고 주장합니다. 이를 완화하기 위해 Gradient similarity 관점을 바탕으로 Student Customized Knowledge Distillation (SCKD)라는 방법을 제안합니다.
Introduction
지식 증류는 일반적으로 거대한 교사(Teacher) 네트워크의 "Dark knowledge"라고 불리는 지식을 경량화된 학생(Student) 네트워크에게 전달하여 성능을 향상시키는 것에 목적이 있습니다. 컴퓨터 비전, 음성 인식, 자연어 처리 등 다양한 태스크에서 지식 증류는 효과적인 기법임을 여러 선행 연구에서 증명되었습니다. 이후, 몇몇 연구자들은 교사와 학생간의 관계에 대해서 연구를 수행합니다. 직관적으로 생각하기에, "Better teachers make better students"라고 생각할 수 있습니다.
하지만, 몇몇 선행 연구에서는 더 크고 좋은 성능을 지니는 교사 모델이 그보다 작은 모델의 교사를 사용하여 지식 증류를 수행했을 때보다 좋지 않다는 것을 발견했습니다 (논문 - TAKD). 그리고 Cho et.al.은 이러한 현상이 ImageNet같은 Large-scale의 데이터일수록 더 심하다는 것을 보여주었습니다 (논문 - ESKD). 두 연구 모두 이러한 현상의 원인으로 교사와 학생 모델 간의 카파시티 불일치(Capacity mismatch)때문이라고 얘기합니다. TAKD에서는 이러한 불일치를 줄이기 위해, 교사와 학생 모델 사이에 Teacher Assistant (TA)라는 중간 사이즈의 모델을 만들어 지식이 스무스하게 전달될 수 있도록 합니다. ESKD에서는 지식 증류의 부정적인 영향을 줄이기 위해 교사의 학습 과정에서 Early stopping 전략을 사용하여 끝까지 수렴되기 이전의 교사를 지식 전달로서 사용합니다. (** Early stop된 큰 교사 모델은 학습이 덜 되었으므로 한 단계 낮은 수준의 교사가 되므로, Capacity의 차이가 줄어든다고 할 수 있음.)
다만 이러한 방법들은 학생 네트워크가 변할 때마다, 적정 수준 (TA 모델 사이즈, Early stop 지점)을 수동적으로 사람이 튜닝해주어야 한다는 번거로움이 존재합니다.
따라서, 본 연구에서는 지식 증류 학습 과정 중에 교사와 학생 네트워크의 그래디언트 유사도 (Gradient similarity)를 바탕으로 자동적으로 이러한 카파시티의 불일치를 해결하는 방법을 제안합니다.
1) 먼저 네트워크 표현 (Representation) 유사성을 확인하여, 학습 단계에서 카파시티 불일치가 지속적으로 발생하지는 않는다는 것을 분석합니다.2) 지식 증류를 Multi-task learning으로 정의하고, 타겟 학생 모델의 변경에 무관하게 적절한 지식 증류를 할 수 있도록 하는 Student Customized Knowledge Distillation (SCKD) 방법을 제시합니다.
논문에서 제안하는 방법은 지식의 종류(Output, Feature)나 Scheme (Single teacher, multi-teachers, or Self-distillation)에 상관없이 기존에 사용되던 지식 증류 방법과 함께 적용될 수 있다는 장점을 지니고 있습니다.
Method
(1) Rethinking Capacity Mismatch Between Student and Teacher
먼저, 저자들은 교사와 학생간의 카파시티 불일치의 발생이 학습 단계에서 지속적으로 발생하는 것이 아니라 간헐적으로 발생한다고 가정하였습니다. 이는 카파시티의 차이 때문에 대부분의 이터레이션(iterations) 동안에는 유용한 지식을 전달받고 있으나, 몇몇 이터레이션에서 학생이 교사를 따라하는 것에 실패하여 부정적인 결과를 초래하는 것을 의미합니다.
저자들은 이러한 현상이 발생하는지를 검증하기 위하여, 뉴럴 네트워크의 표현들 간의 유사도를 측정할 수 있는 Center Kernel Alignment (CKA)라는 방법을 사용합니다.
저자들은 피쳐 증류 (Feature distillation) 중 기본적인 방법인 FitNets을 이용하여 ResNet34와(교사) ResNet18(학생) 모델의 세 번째 블락 6개 레이어와 네 번째 블락의 3개 레이어를 서로 증류합니다. 아래 그림은 CIFAR-100에서 80에폭 정도 학습을 시킨 후, 특정 이터레이션을 샘플링하여 CKA 점수를 시각화한 것입니다.
(*논문에서 해당 부분의 설명과 Figure의 내용이 명확하게 일치하지 않는 것 같습니다. 우선 제가 이해한 방식으로 설명하겠습니다. 추후 저자의 Github이 공개되면 issue로 물어보고 수정하겠습니다.)
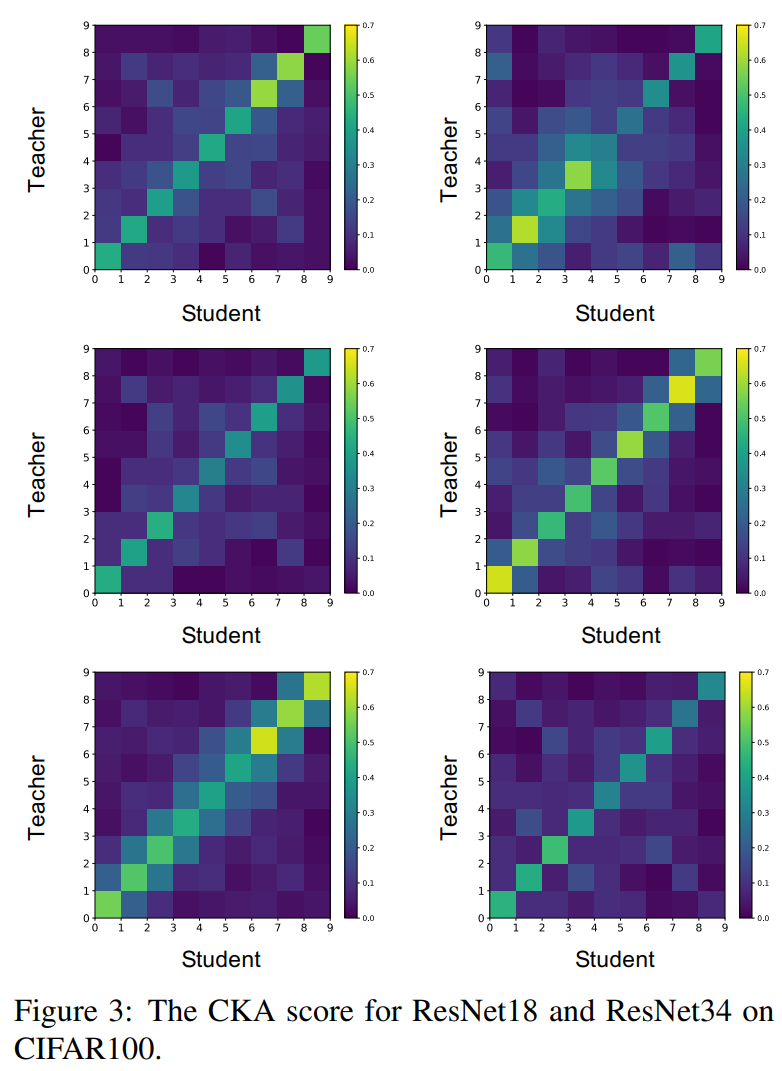
6개의 그림은 서로 다른 이터레이션을 의미하며, 하나의 그림에서 가로축은 학생의 9개 레이어 표현, 그리고 세로축은 교사의 9개 레이어 표현을 의미합니다. 먼저 같은 대각선에 존재하는 CKA의 값은 항상 큰 값을 가집니다. 이는 교사와 학생의 표현이 같은 위치에 있을수록 유사한 표현을 가진다는 것을 의미합니다.
카파시티 불일치와 관련한 해석으로는
1) 같은 이터레이션(하나의 그림)에서 오른쪽 위(Stage 4의 레이어 표현들)는 대체로 높은 CKA 값을 가지지만, 왼쪽 아래나 중간(Stage 3의 표현들)은 상대적으로 낮은 CKA 값을 가집니다. 이는 같은 이터레이션이라고 할지라도 어떤 레이어는 지식 전달이 잘되는반면에 어떤 레이어는 전달이 잘 안되는 것을 의미합니다.
2) 그리고 그림과 그림간의 비교(다른 이터레이션 간의 비교)에서, 같은 위치의 피쳐를 증류하더라도 CKA 점수가 매번 다른 것을 볼 수 있습니다.
이러한 이유로 인해 저자들은 지식 증류 학습 과정에서 교사로부터 유용한 지식을 전달해주기 위한 장치가 필요하다고 주장합니다.
(2) Knowledge Distillation As Multi-Task Learning
위와 같은 카파시티 불일치를 해결하기 위해, 저자들은 먼저 지식 증류를 멀티 태스크 문제로 정의합니다. 분류 문제라고 가정하면, 일반적인 지도(Supervised) 학습에 사용되는 크로스 엔트로피 로스, 아웃풋을 증류하는 KL-divergence 로스, 피쳐를 증류하는 L2 로스를 모두 한 번에 최적화하는 멀티 태스크 문제입니다. 단, 이 때 일반적인 멀티 태스크 러닝과는 다르게 지식 증류에서는 메인이 되는 크로스 엔트로피 로스에 집중합니다.
따라서, 크로스 엔트로피 함수와 지식 증류 손실 함수 간의 Gradient의 유사도를 비교하여 학습 중에 학생에 대한 Negative한 전달을 차단합니다. 기존 지식 증류는 학습 과정 동안에 최적화의 목적이 변화하지 않고 일정합니다. 반면에 본 연구에서 제안하는 SCKD (Student Customized KD)는 학생 모델의 지도 학습 로스와 지식 증류 로스 간의 Gradient의 변화에 따라와 양상에 따라 지식 증류의 연결을 계속 변화시키면서 학습합니다.
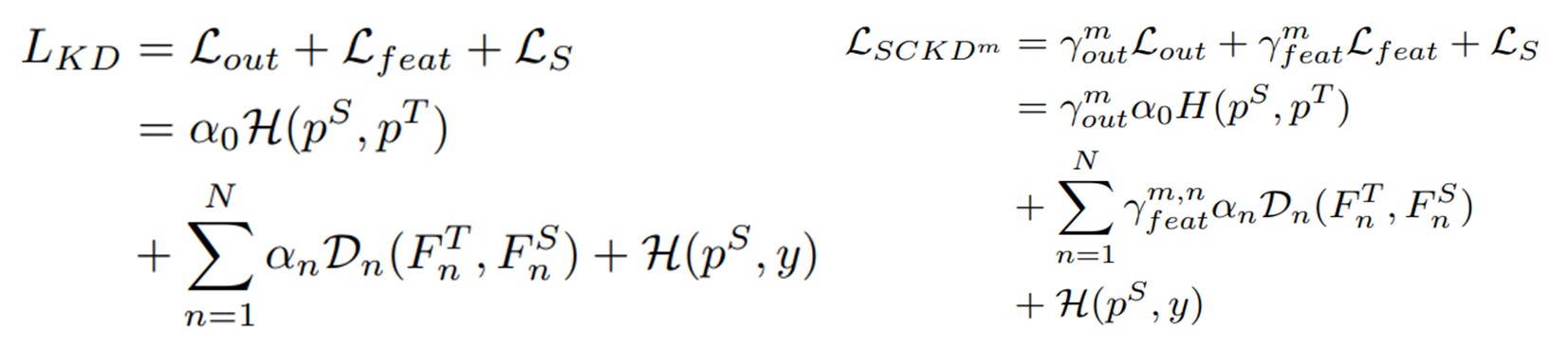
기존의 지식 증류와 손실 함수와 SCKD 방법을 적용한 손실 함수는 위와 같은 차이점이 있습니다. $L_{out}$은 출력을 증류하는 로스, $L_{feat}$는 피쳐를 증류하는 로스, 그리고 $L_{S}$는 지도 학습 로스입니다. 오른쪽의 SCKD 손실 함수는 $\gamma^{m}$ 이라고 하는 학습의 m번째 이터레이션에서의 가중치를 의미합니다. $\gamma^{m}$는 0~1의 값이며, 이는 Gradient에 따라 지식 증류 로스를 얼마나 흘려줄지 결정하게 됩니다.
다음 서브섹션은 Gradient 유사도를 어떻게 계산하는지에 대해 자세히 서술합니다.
(3) Adaptive Knowledge Distillation via Gradient Similarity
저자들은 각 지식 증류 로스와 지도학습 로스간의 Gradient 방향을 측정하기 위해 Gradient 코사인 유사도(Cosine similarity)를 사용합니다. 방법이 생각보다 심플하여서 쉽게 적용할 수 있겠다 생각했는데요, 아래 알고리즘을 보시면 더 쉽게 이해하실 수 있습니다.

매 이터레이션마다 학생 모델의 지도 학습 로스에 대한 Gradient인 나블라_세타(역삼각형인 nabla가 티스토리에서는 입력이 안되네요..)를 구하고, 마찬가지로 지식 증류 로스에 대한 Gradient 역시 구해줍니다. 이후 각 지식 증류마다 (Output, Feature pair 1, Feature pair 2, ...) if cos 으로 시작하는 부분의 조건문을 수행합니다. 이는 지도 학습의 Gradient와 지식 증류 Gradient의 코사인 유사도를 계산하고, $\phi$라는 Threshold를 넘으면 지식 증류의 가중치인$\gamma^{m}$를 1로 만듭니다.
다만, 여기서 알고리즘에 오류가 하나 있는 것 같습니다. 기존 논문의 흐름을 살펴보면 그래디언트 유사도가 높으면 지식 증류 로스를 흘려준다고 논리를 전개해왔는데, if문에 보면 특정 임계치를 넘으면 가중치 $\gamma$를 0으로 만듭니다. 아래는 논문의 Figure 2를 가져온 것인데, 빨간색으로 박스친 부분을 보면 두 Gradient의 코사인 유사도가 0보다 크면 $\gamma$를 1로 만들어주고 있습니다. 따라서, 알고리즘이 잘못 기입된 것으로 보입니다. (혹시 제가 실수했다면 댓글로 알려주시면 정말 감사하겠습니다.)

이어서 얘기하면, 결국 코사인 유사도가 임계치(=0)보다 큰 경우 일반적인 지식 증류처럼 수행하여 Positive한 지식을 전달해주게 되고, 임계치보다 작은 경우에는 지도 학습의 Gradient 방향과 지식 증류의 Gradient 방향이 다르다는 것이므로 Negative한 지식이라고 생각하여 해당 지식을 흘려주지 않게 됩니다.
수식에서는 $\gamma$가 0~1이라고 얘기하면서, 가중치의 역할을 한다고 하였는데 결국에는 스위치처럼 바이너리 형태로 동작시키는 것을 알 수 있었습니다. 방법의 간편함 때문인지 아니면 실제로 실험으로 결정된 것인지는 논문에 나와있지 않았습니다.
그리고 저자들은 Gradient들의 코사인 유사도와 카파시티 불일치가 서로 관련이 있는지에 대해 상관관계 실험을 수행합니다. 따라서, 학습 10에폭동안에 Gradient 코사인 유사도와 CKA Score를 기록하여 피어슨 상관계수를 살펴본 결과 0.6으로 유의미한 양의 상관관계를 보여주었습니다.
Experiments
1) Output-based Knowledge
먼저, 출력 증류에서 지식 증류를 하지 않은 버전(NOKD), 일반적인 KD를 이용한 BLKD, 그리고 Introduction에서 소개했던 카파시티갭 관련 선행 연구인 Teacher Assistant KD (TAKD), Early Stop KD (ESKD)와 비교하였습니다. 역시 성능은 더 좋습니다.

2) Feature-based knowledge
SCKD는 어떤 피쳐나 피쳐의 변환, 또는 피쳐 증류 로스를 제안하는 것이 아니므로 기본 피쳐 증류 방법으로 TOFD를 채택하고, Student Customized라는 방법을 적용하였습니다.

결과는 위의 테이블처럼 TOFD에 비해서 1% 가량의 성능 증가가 있는 것을 보여줍니다.
그리고 가장 Introduction에서도 계속 얘기했었던 "better teacher makes better student”에 대한 중요한 실험을 수행하였습니다. 아래 그림에서처럼 일반적인 지식증류 방법인 KD는 교사의 사이즈가 일정 수준 이상 커지면 성능이 안좋아지는 반면에 SCKD는 꾸준히 좋아지는 것을 볼 수 있습니다.
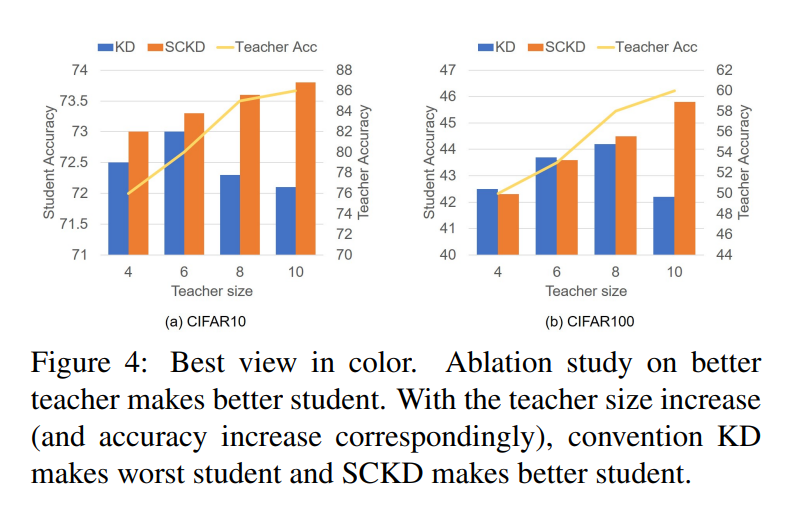
다만, 해당 실험의 아쉬운 점은 교사와 학생으로 Plane CNN 구조를 사용하였는데, 너무 나이브한 모델을 선정한 것이 아닌가 싶습니다. 그리고 이미지넷과 같이 라지 스케일의 데이터에 대한 실험도 보여주었으면 더 좋았을 것 같다는 생각이 들었습니다.